by Bryan Berend | March 23, 2017
About Bryan: Bryan is the Lead Data Scientist at Nielsen.
Introduction
When you first start learning about data science, one of the first things you learn about are classification algorithms. The concept behind these algorithms is pretty simple: take some information about a data point and place the data point in the correct group or class.
A good example is the email spam filter. The goal of a spam filter is to label incoming emails (i.e. data points) as “Spam” or “Not Spam” using information about the email (the sender, number of capitalized words in the message, etc.).
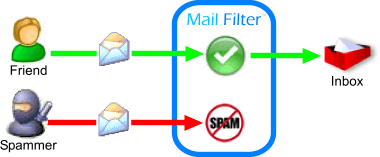
The email spam filter is a good example, but it gets boring after a while. Spam classification is the default example for lectures or conference presentations, so you hear about it over and over again. What if we could talk about a different classification algorithm that was a bit more interesting? Something more nerdy? Something more…magical?

That’s right folks! Today we’ll be talking about the Sorting Hat from the Harry Potter universe. We’ll pull some Harry Potter data from the web, analyze it, and then build a classifier to sort characters into the different houses. Should be fun!
Disclaimer:
The classifier built below is not incredibly sophisticated. Thus, it should be treated as a “first pass” of the problem in order to demonstrate some basic web-scraping and text-analysis techniques. Also, due to a relatively small sample size, we will not be employing classic training techniques like cross-validation. We are simply gathering some data, building a simple rule-based classifier, and seeing the results.
Side note:
The idea for this blog post came from Brian Lange’s excellent presentation on classification algorithms at PyData Chicago 2016. You can find the video of the talk here and the slides here. Thanks Brian!
Step One: Pulling Data from the Web
In case you’ve been living under a rock for the last 20 years, the Sorting Hat is a magical hat that places incoming Hogwarts students into the four Hogwarts houses: Gryffindor, Slytherin, Hufflepuff, and Ravenclaw. Each house has certain characteristics, and when the Sorting Hat is placed on a student’s head, it reads their minds and determines which house they would be the best fit for. By this definition, the Sorting Hat is a multiclass classifier (more than two groups) as opposed to a binary classifier (exactly two groups), like an spam filter.
If we are going sort students into different houses, we’ll need some information about the students. Thankfully, there is a lot of information on harrypotter.wikia.com. This website has articles on nearly every facet of the Harry Potter universe, including students and faculty. As an added bonus, Fandom, the company that runs the website, has an easy-to-use API with lots of great documentation. Hazzah!

We’ll start by importing pandas and requests. The former will be used for organizing the data, while the later will be used to actually make the data requests to the API.
We’ll also need a smart way to loop through all the different students at Hogwarts and record the house they are sorted into by the Sorting Hat (this will be the “truth” that we will compare our results to). By poking around the website, it appears that articles are grouped by “Category”, such as “Hogwarts_students” and “Films_(real-world)”. The Fandom API allows us to list out all of the articles of a given category.
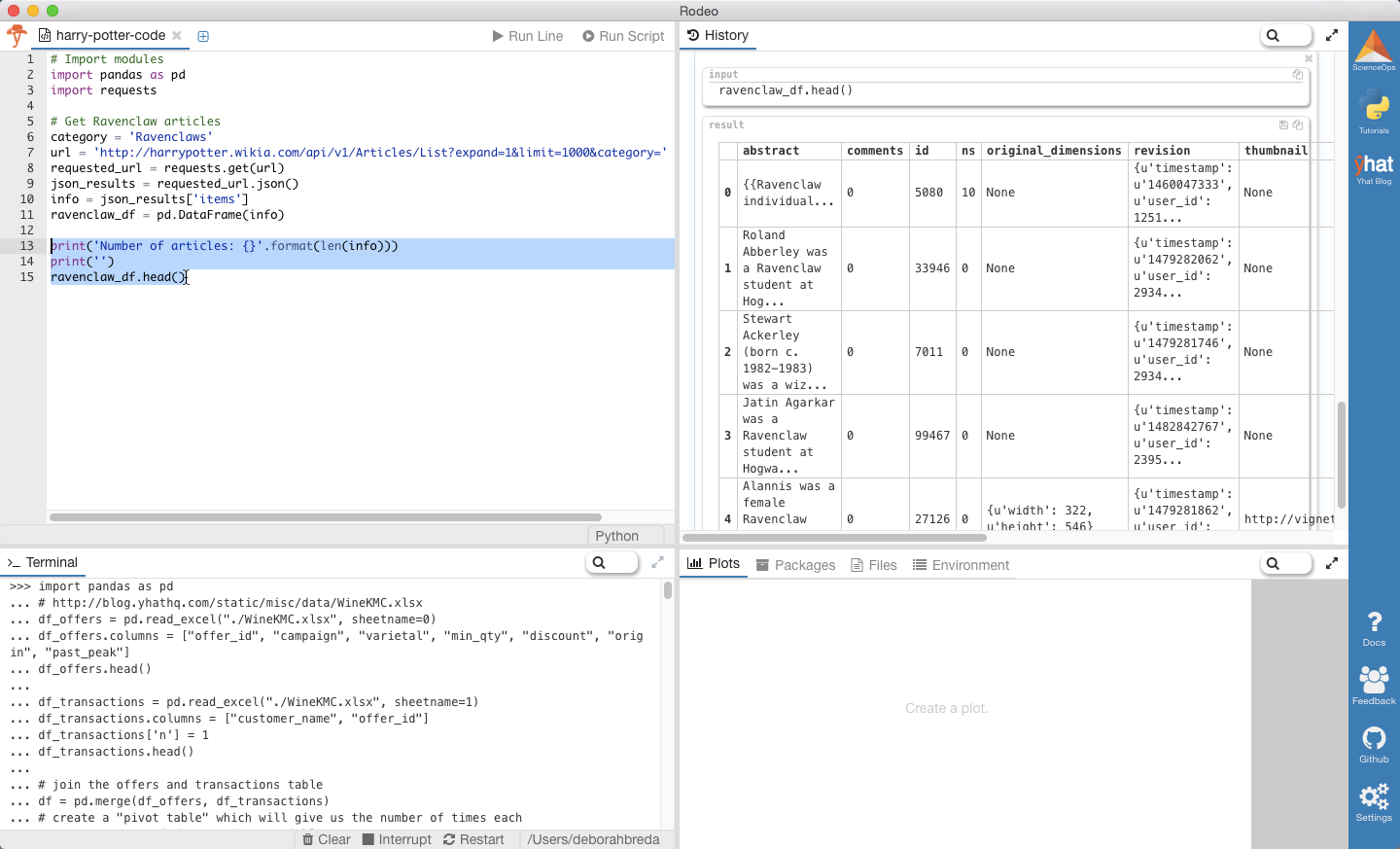
Let’s use Ravenclaw as an example. We’ll get all the data into a variable called info and then we’ll put it into a Pandas DataFrame.
# Import modules
import pandas as pd
import requests
# Get Ravenclaw articles
category = 'Ravenclaws'
url = 'http://harrypotter.wikia.com/api/v1/Articles/List?expand=1&limit=1000&category=' + category
requested_url = requests.get(url)
json_results = requested_url.json()
info = json_results['items']
ravenclaw_df = pd.DataFrame(info)
print('Number of articles: {}'.format(len(info)))
print('')
ravenclaw_df.head()
Number of articles: 158
Yhat note:
If you’re following along in our Python IDE, Rodeo, just copy and paste the code above into the Editor or Terminal tab. You can view results in either the History or Terminal tab. Bonus: Did you know you can drag and drop the tabs and panes to rearrange and resize?
We can see a few things from this:
- The first observation in this list is “Ravenclaw individual infobox”. Since this is not a student, we want to filter our results on the “type” column.
- Unfortunately
ravenclaw_dfdoesn’t have the articles’ contents…just article abstracts. In order to get the contents, we need to use a different API request and query data based on the articles’ ids. - Furthermore, we can write a loop to run over all of the houses and get one dataframe with all the data we need.
# Set variables
houses = ['Gryffindor', 'Hufflepuff', 'Ravenclaw', 'Slytherin']
mydf = pd.DataFrame()
# Gets article ids, article url, and house
for house in houses:
url = "http://harrypotter.wikia.com/api/v1/Articles/List?expand=1&limit=1000&category=" + house + 's'
requested_url = requests.get(url)
json_results = requested_url.json()
info = json_results['items']
house_df = pd.DataFrame(info)
house_df = house_df[house_df['type'] == 'article']
house_df.reset_index(drop=True, inplace=True)
house_df.drop(['abstract', 'comments', 'ns', 'original_dimensions', 'revision', 'thumbnail', 'type'], axis=1, inplace=True)
house_df['house'] = pd.Series([house]*len(house_df))
mydf = pd.concat([mydf, house_df])
mydf.reset_index(drop=True, inplace=True)
# Print results
print('Number of student articles: {}'.format(len(mydf)))
print('')
print(mydf.head())
print('')
print(mydf.tail())
Number of student articles: 748
id title url house
0 33349 Astrix Alixan /wiki/Astrix_Alixan Gryffindor
1 33353 Filemina Alchin /wiki/Filemina_Alchin Gryffindor
2 7018 Euan Abercrombie /wiki/Euan_Abercrombie Gryffindor
3 99282 Sakura Akagi /wiki/Sakura_Akagi Gryffindor
4 99036 Zakir Akram /wiki/Zakir_Akram Gryffindor
id title url house
743 100562 Phylis Whitehead /wiki/Phylis_Whitehead Slytherin
744 3153 Wilkes /wiki/Wilkes Slytherin
745 35971 Ella Wilkins /wiki/Ella_Wilkins Slytherin
746 44393 Rufus Winickus /wiki/Rufus_Winickus Slytherin
747 719 Blaise Zabini /wiki/Blaise_Zabini Slytherin
Getting article contents
Now that we have the article ids, we can start pulling article contents. But some these articles are MASSIVE with incredible amounts of detail…just take a look at Harry Potter’s or Voldemort’s articles!

If we look at some of the most important characters, we’ll see that they all have a “Personality and traits” section in their article. This seems like a logical place to extract information that the Sorting Hat would use in its decision. Not all characters have a “Personality and traits” section (such as Zakir Akram), so this step will reduce the number of students in our data by a significant amount.
The following code pulls the “Personality and traits” section from each article and computes the length of that section (i.e. number of text characters). Then it merges that data with our initial dataframe mydf by “id” (this takes a little while to run).
# Loops through articles and pulls the "Personality and traits" section from each student
# If that section does not exist for a student, we just report a blank string
# This takes a few minutes to run
text_dict = {}
for iden in mydf['id']:
url = 'http://harrypotter.wikia.com/api/v1/Articles/AsSimpleJson?id=' + str(iden)
requested_url = requests.get(url)
json_results = requested_url.json()
sections = json_results['sections']
contents = [sections[i]['content'] for i, x in enumerate(sections) if sections[i]['title'] == 'Personality and traits']
if contents:
paragraphs = contents[0]
texts = [paragraphs[i]['text'] for i, x in enumerate(paragraphs)]
all_text = ' '.join(texts)
else:
all_text = ''
text_dict[iden] = all_text
# Places data into a DataFrame and computes the length of the "Personality and traits" section
text_df = pd.DataFrame.from_dict(text_dict, orient='index')
text_df.reset_index(inplace=True)
text_df.columns = ['id', 'text']
text_df['text_len'] = text_df['text'].map(lambda x: len(x))
# Merges our text data back with the info about the students
mydf_all = pd.merge(mydf, text_df, on='id')
mydf_all.sort_values('text_len', ascending=False, inplace=True)
# Creates a new DataFrame with just the students who have a "Personality and traits" section
mydf_relevant = mydf_all[mydf_all['text_len'] > 0]
print('Number of useable articles: {}'.format(len(mydf_relevant)))
print('')
mydf_relevant.head()
Number of useable articles: 94
| id | title | url | house | text | text_len | |
|---|---|---|---|---|---|---|
| 689 | 343 | Tom Riddle | /wiki/Tom_Riddle | Slytherin | Voldemort was considered by many to be “the mo… | 26924 |
| 169 | 13 | Harry Potter | /wiki/Harry_Potter | Gryffindor | Harry was an extremely brave, loyal, and selfl… | 12987 |
| 726 | 49 | Dolores Umbridge | /wiki/Dolores_Umbridge | Slytherin | Dolores Umbridge was nothing short of a sociop… | 9668 |
| 703 | 259 | Horace Slughorn | /wiki/Horace_Slughorn | Slytherin | Horace Slughorn was described as having a bumb… | 7944 |
| 54 | 4178 | Albus Dumbledore | /wiki/Albus_Dumbledore | Gryffindor | Considered to be the most powerful wizard of h… | 7789 |
Step Two: Getting Hogwarts House Characteristics using NLTK
Now that we have data on a number of students, we want to classify students into different houses. In order to do that, we’ll need a list of the characteristics for each house. We will start with the characteristics on harrypotter.wikia.com.
trait_dict = {}
trait_dict['Gryffindor'] = ['bravery', 'nerve', 'chivalry', 'daring', 'courage']
trait_dict['Slytherin'] = ['resourcefulness', 'cunning', 'ambition', 'determination', 'self-preservation', 'fraternity',
'cleverness']
trait_dict['Ravenclaw'] = ['intelligence', 'wit', 'wisdom', 'creativity', 'originality', 'individuality', 'acceptance']
trait_dict['Hufflepuff'] = ['dedication', 'diligence', 'fairness', 'patience', 'kindness', 'tolerance', 'persistence',
'loyalty']
Notice that all of these characteristics are nouns, which is a good thing; we want to be consistent with our traits. Some of the traits on the wiki were non-nouns, so I changed them as follows:
- “ambitious” (an adjective) – this can be easily changed to ‘ambition’
- “hard work”, “fair play”, and “unafraid of toil” – these multi-word phrases can also be changed to single-word nouns:
- “hard work” –> ‘diligence’
- “fair play” –> ‘fairness’
- “unafraid of toil” –> ‘persistence’
Now that we have a list of characteristics for each house, we can simply scan through the “text” column in our DataFrame and count the number of times a characteristic appears. Sounds simple, right?
Unfortunately we aren’t done yet. Take the following sentences from Neville Longbottom’s “Personality and traits” section:
When he was younger, Neville was clumsy, forgetful, shy, and many considered him ill-suited for Gryffindor house because he seemed timid.
With the support of his friends, to whom he was very loyal, the encouragement of Professor Remus Lupin to face his fears in his third year, and the motivation of knowing his parents’ torturers were on the loose, Neville became braver, more self-assured, and dedicated to the fight against Lord Voldemort and his Death Eaters.
The bold words in this passage should be counted towards one of the houses, but they won’t be because they are adjectives. Similarly, words like “bravely” and “braveness” also would not count. In order to make our classification algorithm work properly, we need to identify synonyms, antonyms, and word forms.
Synonyms
We can explore synonyms of words using the synsets function in WordNet, a lexical database of English words that is included in the nltk module (“NLTK” stands for Natural Language Toolkit). A “synset”, short for “synonym set”, is a collection of synonymous words, or “lemmas”. The synsets function returns the “synsets” that are associated with a particular word.
Confused? So was I when first learned about this material. Let’s run some code and then analyze it.
from nltk.corpus import wordnet as wn
# Synsets of differents words
foo1 = wn.synsets('bravery')
print("Synonym sets associated with the word 'bravery': {}".format(foo1))
foo2 = wn.synsets('fairness')
print('')
print("Synonym sets associated with the word 'fairness': {}".format(foo2))
foo3 = wn.synsets('wit')
print('')
print("Synonym sets associated with the word 'wit': {}".format(foo3))
foo4 = wn.synsets('cunning')
print('')
print("Synonym sets associated with the word 'cunning': {}".format(foo4))
foo4 = wn.synsets('cunning', pos=wn.NOUN)
print('')
print("Synonym sets associated with the *noun* 'cunning': {}".format(foo4))
print('')
# Prints out the synonyms ("lemmas") associated with each synset
foo_list = [foo1, foo2, foo3, foo4]
for foo in foo_list:
for synset in foo:
print((synset.name(), synset.lemma_names()))
Synonym sets associated with the word ‘bravery’: [Synset(‘courage.n.01’), Synset(‘fearlessness.n.01’)]
Synonym sets associated with the word ‘fairness’: [Synset(‘fairness.n.01’), Synset(‘fairness.n.02’), Synset(‘paleness.n.02’), Synset(‘comeliness.n.01’)]
Synonym sets associated with the word ‘wit’: [Synset(‘wit.n.01’), Synset(‘brain.n.02’), Synset(‘wag.n.01’)]
Synonym sets associated with the word ‘cunning’: [Synset(‘craft.n.05’), Synset(‘cunning.n.02’), Synset(‘cunning.s.01’), Synset(‘crafty.s.01’), Synset(‘clever.s.03’)]
Synonym sets associated with the noun ‘cunning’: [Synset(‘craft.n.05’), Synset(‘cunning.n.02’)]
(‘courage.n.01’, [‘courage’, ‘courageousness’, ‘bravery’, ‘braveness’]) (‘fearlessness.n.01’, [‘fearlessness’, ‘bravery’]) (‘fairness.n.01’, [‘fairness’, ‘equity’]) (‘fairness.n.02’, [‘fairness’, ‘fair-mindedness’, ‘candor’, ‘candour’]) (‘paleness.n.02’, [‘paleness’, ‘blondness’, ‘fairness’]) (‘comeliness.n.01’, [‘comeliness’, ‘fairness’, ‘loveliness’, ‘beauteousness’]) (‘wit.n.01’, [‘wit’, ‘humor’, ‘humour’, ‘witticism’, ‘wittiness’]) (‘brain.n.02’, [‘brain’, ‘brainpower’, ‘learning_ability’, ‘mental_capacity’, ‘mentality’, ‘wit’]) (‘wag.n.01’, [‘wag’, ‘wit’, ‘card’]) (‘craft.n.05’, [‘craft’, ‘craftiness’, ‘cunning’, ‘foxiness’, ‘guile’, ‘slyness’, ‘wiliness’]) (‘cunning.n.02’, [‘cunning’])
Okay, that’s a lot of output, so let’s point out some notes & potential problems:
- Typing wn.synsets(‘bravery’) yields two synsets: one for ‘courage.n.01’ and one for ‘fearlessness.n.01’. Let’s dive deeper into what this actually means:
- The first part (‘courage’ and ‘fearlessness’) is the word the synset is centered around…let’s call it the “center” word. This means that the synonyms (“lemmas”) in the synset all mean the same thing as the center word.
- The second part (‘n’) stands for “noun”. You can see that the synsets associated with the word “cunning” include ‘crafty.s.01’ and ‘clever.s.03’ (adjectives). These are here because the word “cunning” is both a noun and an adjective. To limit our results to just nouns, we can specify wn.synsets(‘cunning’, pos=wn.NOUN).
- The third part (’01’) refers to the specific meaning of the center word. For example, ‘fairness’ can mean “conformity with rules or standards” as well as “making judgments free from discrimination or dishonesty”.
We also we see that the synset function gives us some synonym sets that we may not want. The synonym sets associated with the word ‘fairness’ includes ‘paleness.n.02 (“having a naturally light complexion”) and ‘comeliness.n.01’ (“being good looking and attractive”). These are not traits associated with Hufflepuff (although Neville Longbottom grew up to be very handsome), so we need to manually exclude these synsets from our analysis.
Translation: getting synonyms is harder than it looks

Antonyms and Word Forms
After we get all the synonyms (which we’ll actually do in a moment), we also need to worry about the antonyms (words opposite in meaning) and different word forms (“brave”, “bravely”, and “braver” for “bravery”). We can do a lot of the heavy work in nltk, but we will also have to manually create adverbs and comparative / superlative adjectives.
# Prints the different lemmas (synonyms), antonyms, and derivationally-related word forms for the synsets of "bravery"
foo1 = wn.synsets('bravery')
for synset in foo1:
for lemma in synset.lemmas():
print("Synset: {}; Lemma: {}; Antonyms: {}; Word Forms: {}".format(synset.name(), lemma.name(), lemma.antonyms(),
lemma.derivationally_related_forms()))
print("")
Synset: courage.n.01; Lemma: courage; Antonyms: [Lemma(‘cowardice.n.01.cowardice’)]; Word Forms: [Lemma(‘brave.a.01.courageous’)]
Synset: courage.n.01; Lemma: courageousness; Antonyms: []; Word Forms: [Lemma(‘brave.a.01.courageous’)]
Synset: courage.n.01; Lemma: bravery; Antonyms: []; Word Forms: []
Synset: courage.n.01; Lemma: braveness; Antonyms: []; Word Forms: [Lemma(‘brave.a.01.brave’), Lemma(‘audacious.s.01.brave’)]
Synset: fearlessness.n.01; Lemma: fearlessness; Antonyms: [Lemma(‘fear.n.01.fear’)]; Word Forms: [Lemma(‘audacious.s.01.fearless’), Lemma(‘unafraid.a.01.fearless’)]
Synset: fearlessness.n.01; Lemma: bravery; Antonyms: []; Word Forms: []
Putting it all together
The following code creates a list of the synonyms, antonyms, and words forms for each of the house traits described earlier. To make sure we’re exhaustive, some of these might not actually be correctly-spelled English words.
# Manually select the synsets that are relevant to us
relevant_synsets = {}
relevant_synsets['Ravenclaw'] = [wn.synset('intelligence.n.01'), wn.synset('wit.n.01'), wn.synset('brain.n.02'),
wn.synset('wisdom.n.01'), wn.synset('wisdom.n.02'), wn.synset('wisdom.n.03'),
wn.synset('wisdom.n.04'), wn.synset('creativity.n.01'), wn.synset('originality.n.01'),
wn.synset('originality.n.02'), wn.synset('individuality.n.01'), wn.synset('credence.n.01'),
wn.synset('acceptance.n.03')]
relevant_synsets['Hufflepuff'] = [wn.synset('dedication.n.01'), wn.synset('commitment.n.04'), wn.synset('commitment.n.02'),
wn.synset('diligence.n.01'), wn.synset('diligence.n.02'), wn.synset('application.n.06'),
wn.synset('fairness.n.01'), wn.synset('fairness.n.01'), wn.synset('patience.n.01'),
wn.synset('kindness.n.01'), wn.synset('forgivingness.n.01'), wn.synset('kindness.n.03'),
wn.synset('tolerance.n.03'), wn.synset('tolerance.n.04'), wn.synset('doggedness.n.01'),
wn.synset('loyalty.n.01'), wn.synset('loyalty.n.02')]
relevant_synsets['Gryffindor'] = [wn.synset('courage.n.01'), wn.synset('fearlessness.n.01'), wn.synset('heart.n.03'),
wn.synset('boldness.n.02'), wn.synset('chivalry.n.01'), wn.synset('boldness.n.01')]
relevant_synsets['Slytherin'] = [wn.synset('resourcefulness.n.01'), wn.synset('resource.n.03'), wn.synset('craft.n.05'),
wn.synset('cunning.n.02'), wn.synset('ambition.n.01'), wn.synset('ambition.n.02'),
wn.synset('determination.n.02'), wn.synset('determination.n.04'),
wn.synset('self-preservation.n.01'), wn.synset('brotherhood.n.02'),
wn.synset('inventiveness.n.01'), wn.synset('brightness.n.02'), wn.synset('ingenuity.n.02')]
# Function that will get the different word forms from a lemma
def get_forms(lemma):
drfs = lemma.derivationally_related_forms()
output_list = []
if drfs:
for drf in drfs:
drf_pos = str(drf).split(".")[1]
if drf_pos in ['n', 's', 'a']:
output_list.append(drf.name().lower())
if drf_pos in ['s', 'a']:
# Adverbs + "-ness" nouns + comparative & superlative adjectives
if len(drf.name()) == 3:
last_letter = drf.name()[-1:]
output_list.append(drf.name().lower() + last_letter + 'er')
output_list.append(drf.name().lower() + last_letter + 'est')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name().lower()+'ly')
elif drf.name()[-4:] in ['able', 'ible']:
output_list.append(drf.name().lower()+'r')
output_list.append(drf.name().lower()+'st')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name()[:-1].lower()+'y')
elif drf.name()[-1:] == 'e':
output_list.append(drf.name().lower()+'r')
output_list.append(drf.name().lower()+'st')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name().lower()+'ly')
elif drf.name()[-2:] == 'ic':
output_list.append(drf.name().lower()+'er')
output_list.append(drf.name().lower()+'est')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name().lower()+'ally')
elif drf.name()[-1:] == 'y':
output_list.append(drf.name()[:-1].lower()+'ier')
output_list.append(drf.name()[:-1].lower()+'iest')
output_list.append(drf.name()[:-1].lower()+'iness')
output_list.append(drf.name()[:-1].lower()+'ily')
else:
output_list.append(drf.name().lower()+'er')
output_list.append(drf.name().lower()+'est')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name().lower()+'ly')
return output_list
else:
return output_list
# Creates a copy of our trait dictionary
# If we don't do this, then we constantly update the dictariony we are looping through, causing an infinite loop
import copy
new_trait_dict = copy.deepcopy(trait_dict)
antonym_dict = {}
# Add synonyms and word forms to the (new) trait dictionary; also add antonyms (and their word forms) to the antonym dictionary
for house, traits in trait_dict.items():
antonym_dict[house] = []
for trait in traits:
synsets = wn.synsets(trait, pos=wn.NOUN)
for synset in synsets:
if synset in relevant_synsets[house]:
for lemma in synset.lemmas():
new_trait_dict[house].append(lemma.name().lower())
if get_forms(lemma):
new_trait_dict[house].extend(get_forms(lemma))
if lemma.antonyms():
for ant in lemma.antonyms():
antonym_dict[house].append(ant.name().lower())
if get_forms(ant):
antonym_dict[house].extend(get_forms(ant))
new_trait_dict[house] = sorted(list(set(new_trait_dict[house])))
antonym_dict[house] = sorted(list(set(antonym_dict[house])))
# Print some of our results
print("Gryffindor traits: {}".format(new_trait_dict['Gryffindor']))
print("")
print("Gryffindor anti-traits: {}".format(antonym_dict['Gryffindor']))
print("")
Gryffindor traits: [‘bold’, ‘bolder’, ‘boldest’, ‘boldly’, ‘boldness’, ‘brass’, ‘brassier’, ‘brassiest’, ‘brassily’, ‘brassiness’, ‘brassy’, ‘brave’, ‘bravely’, ‘braveness’, ‘braver’, ‘bravery’, ‘bravest’, ‘cheek’, ‘cheekier’, ‘cheekiest’, ‘cheekily’, ‘cheekiness’, ‘cheeky’, ‘chivalry’, ‘courage’, ‘courageous’, ‘courageouser’, ‘courageousest’, ‘courageously’, ‘courageousness’, ‘daring’, ‘face’, ‘fearless’, ‘fearlesser’, ‘fearlessest’, ‘fearlessly’, ‘fearlessness’, ‘gallantry’, ‘hardihood’, ‘hardiness’, ‘heart’, ‘mettle’, ‘nerve’, ‘nervier’, ‘nerviest’, ‘nervily’, ‘nerviness’, ‘nervy’, ‘politesse’, ‘spunk’, ‘spunkier’, ‘spunkiest’, ‘spunkily’, ‘spunkiness’, ‘spunky’]
Gryffindor anti-traits: [‘cowardice’, ‘fear’, ‘timid’, ‘timider’, ‘timidest’, ‘timidity’, ‘timidly’, ‘timidness’]
# Tests that the trait dictionary and the antonym dictionary don't have any repeats among houses
from itertools import combinations
def test_overlap(dict):
results = []
house_combos = combinations(list(dict.keys()), 2)
for combo in house_combos:
results.append(set(dict[combo[0]]).isdisjoint(dict[combo[1]]))
return results
# Outputs results from our test; should output "False"
print("Any words overlap in trait dictionary? {}".format(sum(test_overlap(new_trait_dict)) != 6))
print("Any words overlap in antonym dictionary? {}".format(sum(test_overlap(antonym_dict)) != 6))
Any words overlap in trait dictionary? False Any words overlap in antonym dictionary? False

Step 3: Sorting Students into Houses
The time has finally come to sort students into their houses! Our classification algorithm will work like this:
- For each student, go through their “Personality and traits” section word by word
- If a word appears in a house’s trait list, then we add 1 to that house’s score
- Similarly, if a word appears in a house’s anti-trait list, then we subtract 1 from that house’s score
- The house with the highest score is the one we assign the student to
- If there is a tie, we will simply output “Tie!”
For example, if a character’s “Personality and traits” section was just the sentence “Alice was brave”, then Alice would have a score of 1 for Gryffindor and zero for all other houses; we would sort Alice into Gryffindor.
# Imports "word_tokenize", which breaks up sentences into words and punctuation
from nltk import word_tokenize
# Function that sorts the students
def sort_student(text):
text_list = word_tokenize(text)
text_list = [word.lower() for word in text_list]
score_dict = {}
houses = ['Gryffindor', 'Hufflepuff', 'Ravenclaw', 'Slytherin']
for house in houses:
score_dict[house] = (sum([True for word in text_list if word in new_trait_dict[house]]) -
sum([True for word in text_list if word in antonym_dict[house]]))
sorted_house = max(score_dict, key=score_dict.get)
sorted_house_score = score_dict[sorted_house]
if sum([True for i in score_dict.values() if i==sorted_house_score]) == 1:
return sorted_house
else:
return "Tie!"
# Test our function
print(sort_student('Alice was brave'))
print(sort_student('Alice was British'))
Gryffindor Tie!
Our function seems to work, so let’s apply it to our data and see what we get!
# Turns off a warning
pd.options.mode.chained_assignment = None
mydf_relevant['new_house'] = mydf_relevant['text'].map(lambda x: sort_student(x))
mydf_relevant.head(20)
print("Match rate: {}".format(sum(mydf_relevant['house'] == mydf_relevant['new_house']) / len(mydf_relevant)))
print("Percentage of ties: {}".format(sum(mydf_relevant['new_house'] == 'Tie!') / len(mydf_relevant)))
Match rate: 0.2553191489361702 Percentage of ties: 0.32978723404255317

Hmmm. Those are not the results we were expecting. Let’s try to investigate why Voldemort was sorted into Hufflepuff.

# Voldemort's text data
tom_riddle = word_tokenize(mydf_relevant['text'].values[0])
tom_riddle = [word.lower() for word in tom_riddle]
# Instead of computing a score, we'll list out the words in the text that match words in our traits and antonyms dictionaries
words_dict = {}
anti_dict = {}
houses = ['Gryffindor', 'Hufflepuff', 'Ravenclaw', 'Slytherin']
for house in houses:
words_dict[house] = [word for word in tom_riddle if word in new_trait_dict[house]]
anti_dict[house] = [word for word in tom_riddle if word in antonym_dict[house]]
print(words_dict)
print("")
print(anti_dict)
{‘Slytherin’: [‘ambition’], ‘Ravenclaw’: [‘intelligent’, ‘intelligent’, ‘mental’, ‘individual’, ‘mental’, ‘intelligent’], ‘Hufflepuff’: [‘kind’, ‘loyalty’, ‘true’, ‘true’, ‘true’, ‘loyalty’], ‘Gryffindor’: [‘brave’, ‘face’, ‘bold’, ‘face’, ‘bravery’, ‘brave’, ‘courageous’, ‘bravery’]}
{‘Slytherin’: [], ‘Ravenclaw’: [‘common’], ‘Hufflepuff’: [], ‘Gryffindor’: [‘fear’, ‘fear’, ‘fear’, ‘fear’, ‘fear’, ‘fear’, ‘cowardice’, ‘fear’, ‘fear’]}
As you can see, Slytherin had a score of (1-0) = 1, Ravenclaw had (6-1) = 5, Hufflepuff had (6-0) = 6, and Gryffindor had (8-9) = -1.
It’s also interesting to note that Voldemort’s “Personality and Traits section”, which is the longest of any student, matched with only 31 words in our synonym and antonym dictionaries, which means that other students probably had much lower matched word counts. This means that we are making our classification decision off very little data, which explains the misclaffication rate and the high number of ties.
Conclusions
The classifier we built is not very successful (we do slightly better than simplying guessing), but we have to consider that our approach was pretty simplistic. Modern email spam filters are very sophistocated and don’t just classify based on the presence of certain words, so future improvements to our algorithm should similarly take into account more information. Here’s a short list of ideas for future enhancements:
- Consider which houses other family members were placed
- Use other sections of the the Harry Potter wiki articles, like “Early Life” or the abstract at the beginning of the article
- Instead of taking a small list of traits and their synonyms, create a list of the most frequent words in the “Personality and traits” section for each house and classify based on that.
- Employ more sophisticated text-analysis techniques like sentiment analysis
However, we did learn a lot about APIs and nltk in the process, so at the end of the day I’m calling it a win. Now that we have these tools in our pocket, we have a solid base for future endeavours and can go out and conquer Python just like Neville conquered Nagini.
