In a previous post, I mentioned a little project to provide a pure-python mock of apache spark’s RDD object for testing and quick prototyping. Thanks to some help from contributors, we’ve made a bit of progress and now a good bit of the RDD API is supported, including using the newHadoopAPI with elasticsearch-hadoop, and pulling […]
Author: Will McGinnis
Category Encoders now on conda forge
My scikit-learn compatible library of categorical data encoders (category_encoders) is now published on conda forge! Conda, if you didn’t know, is an open source package manager for python (and other things) developed primarily by continuum analytics. Thanks to continuum developer https://github.com/bollwyvl for doing pretty much all of the work to get it working. Check out the […]
Using twitter-pandas to find friends who don’t follow you back
Over the past couple of months we’ve been gradually working on twitter-pandas, a pandas dataframe based interface to twitter data (powered by tweepy behind the scenes). I’ve posted about the first limited release previously here. The initial release was focused on just replicating the tweepy API as best as we could as a first building […]
Data Science Things Roundup #9
Things got a bit busy and I feel off the wagon posting, but here we are back for the ninth edition of the data science things roundup. If you haven’t seen previous editions, it’s basically just 3 data science or python related articles or packages that I’ve stumbled across recently and thought were interesting. This […]
Projects Update: July 2016
About a quarter ago (April), I posted my first regular update on all of the various projects I’m working on. As side projects tend to go, some fall into and out of favor, and occasionally new ones crop up. As I develop on projects, I post regular updates, but it’s helpful to me (and hopefully […]
PyData Atlanta Recap: July 2016
Previously I posted a little bit about the PyData Atlanta meetup in June, where I presented a lightning talk on my project: git-pandas. The July meetup was this past Wednesday, and it was as always very interesting so I thought I would do a quick recap of what all was presented. Main The main talk this […]
PyData Atlanta Meetup: git pandas talk
One of my favorite meetups in Atlanta is the PyData meetup, monthly at General Assembly (a pretty nice venue in ponce city market). I try to goto a few meetups a month around town, and this is the only one I’ve been to that is consistently well organized, interesting, and relaxed. It’s less like a […]
Twitter-Pandas, first release
Thanks to some great help from contributors, we’ve just pushed the first release of twitter pandas, v0.0.1. The first release is aimed at replicating the data-providing (no create/update/delete functions) from the tweepy API with the git-pandas style pandas interface. To install twitterpandas, just use pip pip install twitterpandas And then you can use it right […]
Beyond One-Hot: incremental improvements in categorical encoding
The beyond-one-hot project has started to grow up. Last fall, I did a couple of posts comparing different methods of encoding categorical variables for machine learning problems. You can check them out here and here respectively. Those posts were pretty well received, so the hacky little script that was used to make the plots got […]
Introducing unified glob-syntax in git-pandas
In an effort to improve the user interface to git-pandas, I’m introducing a new way of specifying which files in a repository you care about, which will become the sole way of specifying this kind of thing in version 2.0.0. Currently, for any given function, you can specify a list of extensions you’d like to […]
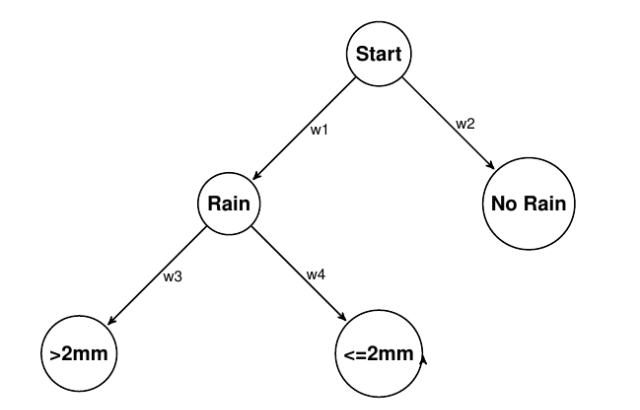
Mixed-mode estimation in petersburg
A couple of months ago I posted an overview of simple estimation of hierarchical events using python and petersburg. At the time it probably seemed a little bit trivial, just building a structured frequency model and drawing samples from it. But I have finally implemented the next step to complete the intended functionality. This post […]
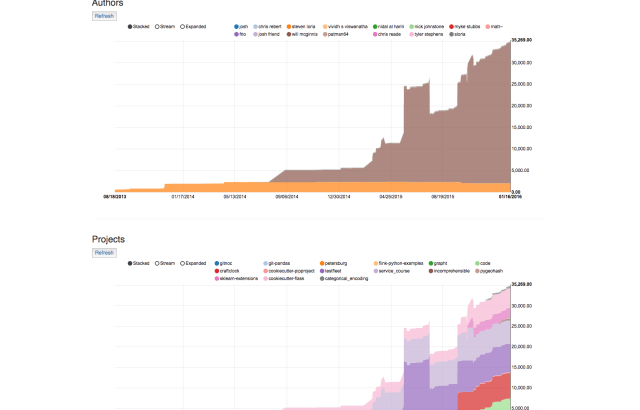
Parallelizing cumulative blame in git-pandas with joblib
It’s been a little while since I’ve posted anything about git-pandas, as I’ve been working on getting a sister project, twitter-pandas up and running. Work has continued though, and today I’d like to show a currently experimental feature, parallelized cumulative blame. Cumulative blame is one of the more popular features used in git-pandas, as it […]
Data Science Things Roundup #7
This weeks edition of the Data Science Things Roundup is pretty python-heavy, as opposed to previous editions that were a bit more machine learning and dataviz heavy. At the end of the day, some kind of software is backing most of data science, so getting a bit lower level can be useful sometimes. This week […]
Twitter-Pandas: like git-pandas, but for twitter.
I’ve got a python library that I’ve posted here before, that people seem to like called git-pandas. The idea is to provide a pandas-centric interface to the data in a git repository. To start with, we added simple representations of common datasets (commits, file changes, branches, etc), and as the library grew, we added in […]
Data Science Things Roundup #6
Time again for the weekly data science things roundup. If you haven’t seen this before, check out some of the previous ones to get a feel for it. Each Tuesday I run through 3 things I’ve found interesting and bookmarked recently, generally related to python and data science (with some admitted diversions). This week is […]