If you’ve worked on a Python project that has more than one file, chances are you’ve had to use an import statement before. Even for Pythonistas with a couple of projects under their belt, imports can be confusing! You’re probably reading this because you’d like to gain a deeper understanding of imports in Python, particularly […]
Category: SQL
Top 10 Must-Watch PyCon Talks
For the past three years, I’ve had the privilege of attending the Python Conference (PyCon) in the United States. PyCon US is a yearly event where Pythonistas get together to talk and learn about Python. It’s a great place to learn, meet new fellow Python devs, and get some seriously cool swag. The first time […]

The Best Python Books
Python is an amazing programming language. It can be applied to almost any programming task, allows for rapid development and debugging, and brings the support of what is arguably the most welcoming user community. Getting started with Python is like learning any new skill: it’s important to find a resource you connect with to guide […]
Python Aggregate UDFs in Pyspark
Pyspark has a great set of aggregate functions (e.g., count, countDistinct, min, max, avg, sum), but these are not enough for all cases (particularly if you’re trying to avoid costly Shuffle operations). Pyspark currently has pandas_udfs, which can create custom aggregators, but you can only “apply” one pandas_udf at a time. If you want to […]

What Can I Do With Python?
You’ve done it: you’ve finished a course or finally made it to the end of a book that teaches you the basics of programming with Python. You’ve mastered lists, dictionaries, classes, and maybe even some object oriented concepts. So… what next? Python is a very versatile programming language, with a plethora of uses in a […]
Python Application Layouts: A Reference
Python, though opinionated on syntax and style, is surprisingly flexible when it comes to structuring your applications. On the one hand, this flexibility is great: it allows different use cases to use structures that are necessary for those use cases. On the other hand, though, it can be very confusing to the new developer. The […]
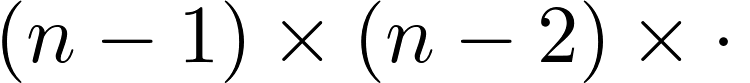
Itertools in Python 3, By Example
It has been called a “gem” and “pretty much the coolest thing ever,” and if you have not heard of it, then you are missing out on one of the greatest corners of the Python 3 standard library: itertools. A handful of excellent resources exist for learning what functions are available in the itertools module. […]
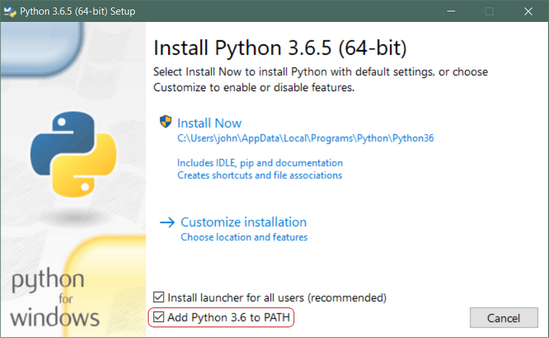
Python 3 Installation & Setup Guide
To get started working with Python 3, you’ll need to have access to the Python interpreter. There are several common ways to accomplish this: Python can be obtained from the Python Software Foundation website at python.org. Typically, that involves downloading the appropriate installer for your operating system and running it on your machine. Some operating […]
Pythonic Data Cleaning With NumPy and Pandas
Data scientists spend a large amount of their time cleaning datasets and getting them down to a form with which they can work. In fact, a lot of data scientists argue that the initial steps of obtaining and cleaning data constitute 80% of the job. Therefore, if you are just stepping into this field or […]

Introduction to AWS for Data Scientists
These days, many businesses use cloud based services; as a result various companies have started building and providing such services. Amazon began the trend, with Amazon Web Services (AWS). While AWS began in 2006 as a side business, it now makes $14.5 billion in revenue each year. Other leaders in this area include: Google—Google Cloud […]
Simplifying Offline Python Deployments With Docker
In cases when a production server does not have access to the Internet or to the internal network, you will need to bundle up the Python dependencies (as wheel files) and interpreter along with the source code. This post looks at how to package up a Python project for distribution internally on a machine cut […]
Postgres Internals: Building a Description Tool
In previous blog posts, we have described the Postgres database and ways to interact with it using Python. Those posts provided the basics, but if you want to work with databases in production systems, then it is necessary to know how to make your queries faster and more efficient. To understand what efficiency means in […]

Will’s Noise
Will’s NoiseBowl Game Pick ’em ResultsOn taking things too seriously: holiday editionElote: a python package of rating systemsRipyr: sampled metrics on datasets using python’s asyncioCategory Encoders v1.2.5 ReleaseStanding Peachtree ParkData Science Things Roudup #11Modernizing Pedalwrencher: whatever that means.Git-pandas caching for faster analysisCategory Encoders v1.2.4 Release http://www.willmcginnis.com Data Science, Technology, Atlanta Mon, 25 Dec 2017 00:52:27 […]

Pandas Concatenation Tutorial
You’d be hard pressed to find a data science project which doesn’t require multiple data sources to be combined together. Often times, data analysis calls for appending new rows to a table, pulling additional columns in, or in more complex cases, merging distinct tables on a common key. All of these tricks are handy to […]
Building a Simple Web App with Bottle, SQLAlchemy, and the Twitter API
This is a guest blog post by Bob Belderbos. Bob is a driven Pythonista working as a software developer at Oracle. He is also co-founder of PyBites, a Python blog featuring code challenges, articles, and news. Bob is passionate about automation, data, web development, code quality, and mentoring other developers. Last October we challenged our […]