By default, the content of an OpenStack Swift object cannot be greater than 5 GB. However, you can use a number of smaller objects to construct a large object via the concept of segmentation. From OpenStack Large Object Support, “Segments of the larger object are uploaded and a special manifest file is created that, when downloaded, sends all the segments concatenated as a single object.” This “user manifest” design exists in order to provide a transparent download of large objects to the client and still provide the uploading client with a clean API to support segmented uploads.1

While working with large data sets, we stumbled into a challenge around the exact mechanics to represent a 14Gb file as a singular entity within IBM® Object Storage for Bluemix®. This blog post shares what we learned about the creation of OpenStack Swift Manifest objects.
Background: A 3rd party uploaded 61 separate files (segment files) into our IBM Bluemix Object Storage container, but failed to upload a corresponding manifest file. Instead, they shared a manifest file that outlined the details for each HTTP PUT request with no further context on what it was or how to use it. The contents of the file were similar to …
|
1 2 3 4 5 6 |
{‘path’: ‘/somecontainer/someprefix-NjT2OURYBq’, ‘etag’: ‘ebc7d0d4718d8513fd5cdcf76de66f2a’, ‘size_bytes’: 234003629}, {‘path’: ‘/somecontainer/someprefix-zVliDpHox4’, ‘etag’: ‘2814e177b9371770caf13902d6587373’, ‘size_bytes’: 234521937}, {‘path’: ‘/somecontainer/someprefix-5lHhJcyjEX’, ‘etag’: ‘843fbdfb493b484b035436e0bb782560’, ‘size_bytes’: 241395892}, {‘path’: ‘/somecontainer/someprefix-Q7xSsBprGK’, ‘etag’: ’05d09e28c8994cf5f9833c9dee6494a7′, ‘size_bytes’: 237095501}, {‘path’: ‘/somecontainer/someprefix-8pQIF4w1GR’, ‘etag’: ‘e0d912fc4b88961c33ecfe70e64a7855’, ‘size_bytes’: 226289048}, ... |
Our Challenge: Referencing 61 individual files within our IBM Bluemix Apache Spark Service Jupyter Notebook seemed wrong. We wanted to pull in the entirety of the data by referencing a single Openstack swift url (e.g. swift://foo/man/… ) and without having to re-upload the entire series of files again. We suspected that the provided manifest file would prove useful, but had difficulty finding easy steps on using it in conjunction with OpenStack Swift and the IBM Bluemix Object Storage service. We were largely ignorant of how OpenStack Large Object support worked and how to use OpenStack Swift Manifest Objects. Sooo … here is our journey in the spirit of sharing 
Options: IBM Object Storage for Bluemix provides you with access to a fully provisioned OpenStack Object Storage (Swift) account to manage your data. IBM Object Storage for Bluemix uses OpenStack Identity (Keystone) for authentication and can be accessed directly by using Swift Object Storage API v1 calls2. OpenStack Large Object Support is enabled and available for the IBM Object Storage for Bluemix service. But don’t take my word for it … issuing a HTTP GET request to the /info endpoint [https://dal.objectstorage.open.softlayer.com/info] confirms this via the presence of a slo section. To support as many use cases as possible, OpenStack swift supports two (2) flavors:
- Static Large Objects (SLO) – Relies on a user provided manifest file. Advantageous for use cases when the developer wants to “mashup” objects from multiple containers and reference them in a self-generated manifest file. This gives you immediate access to the concatenated object after the manifest is accepted. Uploading segments into separate containers provides the opportunity for improved concurrent upload speeds. On the downside, the concatenated object’s definition is frozen until the manifest is replaced.
- Dynamic Large Objects (DLO) – Relies on a container-listing zero-byte manifest file. Advantageous for use cases when the developer might add/remove segments from the manifest at any time. A few disadvantages include reliance on eventual consistent container listings which means there may be some delay before access to the full concatenated object is available. There is also a requirement for all segments to be in a single container, which can limit concurrent upload speeds.
Reader Tip: Consider jumping to the Easy Button section if time is short and you’re looking to solve the happy path (e.g. Need to upload a local >5 Gb file into IBM Bluemix Object Storage based on OpenStack swift).
Game Plan:
- Obtain/Identify an IBM Object Storage instance and gather credentials
- Leverage credentials to determine Swift Object Storage API URL
- Depending on desired flavor of large object storage, HTTP PUT appropriate manifest file.
- Reference created manifest file to gain access to a concatenated representation of the file segments
Mechanics to Solve Our Challenge:
- Instantiate/Inspect an IBM Object Storage for Bluemix service instance to confirm allocated storage resources and generated Keystone Authentication credentials. Specifically, we care about 3 values within credentials: {projectId}, {userId} and {password}. You can find these creds within the Bluemix Web UI under the Service Credentials section of the service …
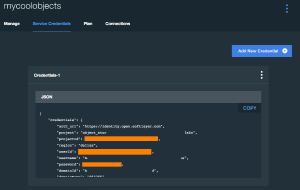
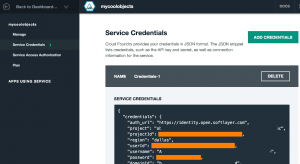
or via the Cloud Foundry (cf) Command Line Interpreter (CLI) …1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
$ cf service–keys {name_of_your_object_storage_service}
Getting keys for service instance {name_of_your_object_storage_service} as {your_username}...
name
Credentials–1
$ cf service–keys {name_of_your_object_storage_service} Credentials–1
Getting key Credentials–1 for service instance {name_of_your_object_storage_service} as {your_username}...
{
“auth_url”: “https://identity.open.softlayer.com”,
“domainId”: “nice_long_hex_value”,
“domainName”: “some_number”,
“password”: “not_gonna_tell_you”,
“project”: “object_storage_hex_value”,
“projectId”: “project_hex_value”,
“region”: “dallas”,
“userId”: “another_fine_hex_value”,
“username”: “some_text_with_hex_values”
}
Step 1 Complete!
- Execute a HTTP POST Request to {auth_url}/v3/auth/tokens which includes the credentials from Step #1 entered within the appropriate fields of the HTTP POST JSON body
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
POST /v3/auth/tokens HTTP/1.1
Host: identity.open.softlayer.com
Content–Type: application/json
Cache–Control: no–cache
{
“auth”: {
“identity”: {
“methods”: [
“password”
],
“password”: {
“user”: {
“id”: “another_fine_hex_value”,
“password”: “not_gonna_tell_you”
}
}
},
“scope”: {
“project”: {
“id”: “project_hex_value”
}
}
}
}
This can be accomplished with a variety of tools ranging from Google Chrome Postman to curl.
For example, …1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
$ curl –X POST –H “Content-Type: application/json” –H “Cache-Control: no-cache” –d ‘{
“auth”: {
“identity”: {
“methods”: [
“password”
],
“password”: {
“user”: {
“id”: “another_fine_hex_value”,
“password”: “not_gonna_tell_you”
}
}
},
“scope”: {
“project”: {
“id”: “project_hex_value”
}
}
}
}‘ “https://identity.open.softlayer.com/v3/auth/tokens”
This should result in a 500+ Line JSON Response BODY similar to …
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
{
“token”: {
“methods”: [
“password”
],
“roles”: [
{
“id”: “redacted”,
“name”: “ObjectStorageOperator”
}
],
“expires_at”: “2016-03-09T20:26:39.192753Z”,
“project”: {
“domain”: {
“id”: “some_hex_value”,
“name”: “some_int”
},
“id”: “another_hex_value”,
“name”: “one_more_hex_value”
},
“catalog”: [
...
{
“endpoints”: [
{
“region_id”: “london”,
...
},
{
...
},
{
“region_id”: “dallas”,
“url”: “https://dal.objectstorage.open.softlayer.com/v1/AUTH_”,
“region”: “dallas”,
“interface”: “public”,
“id”: “some_unique_id”
},
{
...
},
{
...
},
{
...
}
],
“type”: “object-store”,
“id”: “hex_values_rock”,
“name”: “swift”
},
...
],
“extras”: {},
“user”: {
“domain”: {
“id”: “hex_value”,
“name”: “another_fine_int”
},
“id”: “tired_of_hex_values_yet?”,
“name”: “cheers_one_more_hex_value_for_the_road”
},
...
}
}
Specifically, we want to identify the Swift Object Storage API url
1
https://dal.objectstorage.open.softlayer.com/v1/AUTH_some-hex-value
linked to your desired object storage region (dallas, london, …) and associated with a public interface. This will be found within the endpoints section which includes the name “swift”. This is illustrated in the highlighted lines of the JSON Response body above. Even more importantly, within the generated HTTP Response Header of this /v3/auth/tokens call is an authentication token that we also need to record to facilitate subsequent authenticated HTTP API calls.
Here is a sample of the HTTP Response Headers
1
2
3
4
5
6
7
8
9
10
Connection: Keep–Alive
Content–Length: 12089
Content–Type: application/json
Date: Wed, 09 Mar 2016 19:26:39 GMT
Keep–Alive: timeout=5, max=21
Server: Apache/2.4.6 (CentOS) OpenSSL/1.0.1e–fips mod_wsgi/3.4 Python/2.7.5
Vary: X–Auth–Token
X–Subject–Token: gAAAAABW4Hjv5O8yQRwYbkV81s7KC0mTxlh_tXTFtzDEf3ejsP_CByfvvupOeVWWcWrB6pfVbUyG5THZ6qM1–BiQcBUo1WJOHWDzMMrEB5nru69XBd–J5f5GISOGFjIxPPnNmEDZT_pahnBwaBQiJ8vrg9p5obdtRJeuxk7ADVRQFcBcRhAL–PI
x–openstack–request–id: req–26a078fe–d0a7–4a75–b32d–89d3461c55f1
The X-Subject-Token is the important response header. Its value will be reused within all subsequent HTTP Request Headers using the header X-Auth-Token. Obvious, right?
Step 2 Complete!
- Now for the payoff! As you’ll recall, our original problem pertained to 61 segmented files which had already been uploaded to a single container within our object storage service. We were also given a manifest file outlining the specific file paths, ETag values and file sizes. The availability of this file makes it very straight-forward to pursue creation of a Static Large Object (SLO). As a bonus, since the segments also honored a specific prefix naming convention and were co-located within a single container – we can also pursue creation of a Dynamic Large Object (DLO). Let’s walk through both approaches:
SLO
A carefully crafted HTTP PUT request needs to be made to the Swift Object Storage API Url which includes a valid X-Auth-Token request header, a query string parameter named multipart-manifest with an assigned value of “put” and a valid body containing an array of dict objects that represent a single manifest of all segmented files:
1
2
3
4
5
6
7
8
9
10
11
12
PUT /v1/AUTH_some–hex–value/name_of_any_existing_container/name_of_file_with_any_extension?multipart–manifest=put HTTP/1.1
Host: dal.objectstorage.open.softlayer.com
Content–Type: text/csv
X–Auth–Token: value–obtained–from–X–Subject–Token–Response–Header
Cache–Control: no–cache
[{‘path’: ‘/somecontainer/someprefix-zVliDpHox4’, ‘etag’: ‘2814e177b9371770caf13902d6587373’, ‘size_bytes’: 234521937},
{‘path’: ‘/somecontainer/someprefix-5lHhJcyjEX’, ‘etag’: ‘843fbdfb493b484b035436e0bb782560’, ‘size_bytes’: 241395892},
{‘path’: ‘/somecontainer/someprefix-Q7xSsBprGK’, ‘etag’: ’05d09e28c8994cf5f9833c9dee6494a7′, ‘size_bytes’: 237095501},
{‘path’: ‘/somecontainer/someprefix-8pQIF4w1GR’, ‘etag’: ‘e0d912fc4b88961c33ecfe70e64a7855’, ‘size_bytes’: 226289048},
...]
or via curl …
curl –X PUT –H “Content-Type: text/csv” –H “X-Auth-Token: value-obtained-from-X-Subject-Token-Response-Header” –H “Cache-Control: no-cache” –d ‘[{‘path‘: ‘/somecontainer/someprefix–zVliDpHox4‘, ‘etag‘: ‘2814e177b9371770caf13902d6587373‘, ‘size_bytes‘: 234521937}, {‘path‘: ‘/somecontainer/someprefix–5lHhJcyjEX‘, ‘etag‘: ‘843fbdfb493b484b035436e0bb782560‘, ‘size_bytes‘: 241395892}, {‘path‘: ‘/somecontainer/someprefix–Q7xSsBprGK‘, ‘etag‘: ‘05d09e28c8994cf5f9833c9dee6494a7‘, ‘size_bytes‘: 237095501}, {‘path‘: ‘/somecontainer/someprefix–8pQIF4w1GR‘, ‘etag‘: ‘e0d912fc4b88961c33ecfe70e64a7855‘, ‘size_bytes’: 226289048},
...]‘ “https://dal.objectstorage.open.softlayer.com/v1/AUTH_some-hex-value/name_of_any_existing_container/name_of_file_with_any_extension?multipart-manifest=put”
If all goes well, an HTTP Response Code of 201 should be returned. To validate, you can open your IBM Bluemix Object Storage Service dashboard and observe creation of the “name_of_file_with_any_extension” manifest file within the name_of_any_existing_container. It should show an aggregated size which matches the sum of all segmented files. This new manifest file can now be singularly referenced and represents a collection of the 61 individual segment files. For example, within a Jupyter notebook we loaded the data using syntax similar to “swift://name_of_any_existing_container.spark/name_of_file_with_any_extension”. Sweet!
DLO
A carefully crafted HTTP PUT request needs to be made to the Swift Object Storage API Url which includes a valid X-Auth-Token request header, a required request header named X-Object-Manifest and an optional Content-Length request header with a value of 0:
1
2
3
4
5
6
7
8
PUT /v1/AUTH_some–hex–value/name_of_any_existing_container/name_of_file_with_any_extension HTTP/1.1
Host: dal.objectstorage.open.softlayer.com
Content–Type: application/json
X–Auth–Token: value–obtained–from–X–Subject–Token–Response–Header
Content–Length: 0
X–Object–Manifest: name_of_container_which_holds_the_segmented_files/common_prefix_label_to_match_against_for_all_segmented_files
Cache–Control: no–cache
or via curl …
1
curl –X PUT –H “Content-Type: application/json” –H “X-Auth-Token: value-obtained-from-X-Subject-Token-Response-Header” –H “Content-Length: 0” –H “X-Object-Manifest: name_of_container_which_holds_the_segmented_files/common_prefix_label_to_match_against_for_all_segmented_files” –H “Cache-Control: no-cache” –d ” “https://dal.objectstorage.open.softlayer.com/v1/AUTH_some-hex-value/name_of_any_existing_container/name_of_file_with_any_extension”
If all goes well, an HTTP Response Code of 201 should be returned. To validate, this new zero-byte sized manifest file can now be singularly referenced and represents a collection of the 61 individual segment files. For example, within a Jupyter notebook we loaded the data using syntax similar to “swift://name_of_any_existing_container.spark/name_of_file_with_any_extension”. What’s really cool about this approach is that in the future we could choose to upload a 62nd segment file into the same container area and if we follow the common prefix label provided earlier within the X-Object-Manifest header – then our manifest will magically auto-include the new data with no additional editing of the manifest itself. Dynamic indeed!
Mission accomplished!
Supporting Resources: Creating a special manifest to represent many segmented objects needn’t be hard within IBM Bluemix Object Storage. As we’ve seen, this provides the significant advantage of dealing with data that is larger than 5Gb in size – which is often the case for larger data workloads. However, keep in mind that manifest files can be created for segmented data files aggregating to any size. We’ve explored the pros and cons of creating Static or Dynamic Large Objects and shown the HTTP REST API mechanics to achieve either. Our team has created a Bash Script to help with segmentation of large files into specified chunk sizes while avoiding mid-line splits. We recommend reading the IBM Bluemix Object Storage documentation. We also encourage readers to learn about features found within the excellent Python OpenStack Swift Client, and more specifically the swift upload command.
Easy Button: At this point, you may be wondering if there is a way to obtain a SLO manifest containing all of the segemented ETAG and size values in a JSON format or if the process is easier when the large file is available to you locally rather than our odd situation. The answer is an emphatic YES. The Python OpenStack Swift Client generally provides automatic manifest creation when uploading a single large file as illustrated below.
Example: Locally stored large file needs to be uploaded to Object Storage
Approach: Use the Python Swift Client upload feature with appropriate arguments.
SLO:
|
1 2 3 4 5 6 7 8 9 10 11 |
$ swift —os–auth–url=https://identity.open.softlayer.com/v3 —os–user–id=some_hex_value —os–password=“weird_characters” —os–project–id=another_hex_value —os–region–name=dallas –V 3 upload my_object_storage_container_name –S int_seg_size_in_bytes my_local_large_file_with_some_extension —use–slo my_local_large_file_with_some_extension segment 3 my_local_large_file_with_some_extension segment 1 my_local_large_file_with_some_extension segment 2 my_local_large_file_with_some_extension segment 0 my_local_large_file_with_some_extension/1443450560.000000/160872806/52428800/00000002 my_local_large_file_with_some_extension/1443450560.000000/160872806/52428800/00000003 my_local_large_file_with_some_extension/1443450560.000000/160872806/52428800/00000001 my_local_large_file_with_some_extension/1443450560.000000/160872806/52428800/00000000 my_local_large_file_with_some_extension |
Two (2) things happen. A new container named my_object_storage_container_name_segments is created to hold the segmented files and a new manifest file named my_local_large_file_with_some_extension is generated. As discussed earlier, this manifest should show the aggregated size of all segments that it represents. If you’d like to grab a copy of this SLO manifest for additional hacking, version control or inspection … you’ll need to obtain a valid X-Auth-Token (described above) and issue a HTTP GET request with a modified query-string parameter of get:
|
1 |
curl –X GET –H “Content-Type: text/csv” –H “X-Auth-Token: value-obtained-from-X-Subject-Token-Response-Header” –H “Cache-Control: no-cache” “https://dal.objectstorage.open.softlayer.com/v1/AUTH_some-hex-value/name_of_any_existing_container/name_of_file_with_any_extension?multipart-manifest=get” |
DLO:
|
1 2 3 4 5 6 |
$ swift —os–auth–url=https://identity.open.softlayer.com/v3 —os–user–id=some_hex_value —os–password=“weird_characters” —os–project–id=another_hex_value —os–region–name=dallas –V 3 upload my_object_storage_container_name –S int_seg_size_in_bytes my_local_large_file_with_some_extension my_local_large_file_with_some_extension segment 3 my_local_large_file_with_some_extension segment 1 my_local_large_file_with_some_extension segment 2 my_local_large_file_with_some_extension segment 0 |
Two (2) things happen. A new container named my_object_storage_container_name_segments is created to hold the segmented files and a new manifest file named my_local_large_file_with_some_extension is generated. As discussed earlier, this manifest is a zero-byte sized file and represents ALL files located within a single container that follow a described naming prefix convention.
Food for Thought
- OpenStack manifests allow you to solve a problem like the one we faced … handling of pre-existing segmented uploads that are missing a manifest entry point within your Object Storage
- OpenStack manifests allow you to shape a variety of alternative entry-points to represent varying sizes and composition of data segments. For example, the information within this article provides you with the steps to create a variety of manifest entry points that can represent one-half, one-quarter or even 1/61 of your large file dataset.
- Python OpenStack Swift client is a great tool for basic uploading and segmentation of large files into IBM Bluemix Object Storage
- Static Large Object (SLO) and Dynamic Large Object (DLO) each possess unique characteristics that should be carefully considered against your usecase. A manifest can be created for an aggregate of any size. There is NO requirement that the aggregate size of the segments be > 5Gb, it just happens to be the most common reason for needing a manifest.
- Leveraging Swift Storlets, I stumbled across an interesting blog post that recommended SLOs as a great approach to facilitate Storlet use cases where they need to run on several objects. This was necessary because storlets currently only run on a single stream.
In conclusion, whether you need a 100% representation using the Python OpenStack Swift Client upload feature or a partial representation via the OpenStack Storage APIs to facilitate large data analysis and more efficient notebook designs with faster processing times, you’ll be able to access the right size of data for your task.
1 http://docs.openstack.org/developer/swift/overview_large_objects.html
2 http://docs.openstack.org/developer/swift/overview_large_objects.html#direct-api
Early in my career, specialized in melting plastic and debating with ISO auditors. Later, tested software test tools – envision a person measuring rulers in a ruler factory. After a promotion, I managed a team great at breaking software. I was also the test organization’s performance expert, assessing application throughput/speed and recommending fixes to make applications go faster. Later on, I worked on gluing non-IBM and IBM software together and showing customers how easy it was to do. As a facilitator to support the CEO’s office, I organized studies for our executive leadership by gathering people and steering chats to look at disruptive technologies and see where new money could be made. I’m currently a member of the amazing IBM jStart team. We explore the “art of the possible”, have an aversion for saying “it can’t be done” and love learning through direct client engagement. My general focus has been on cloud-related emerging technologies facilitated by our Cloud Foundry based Platform as a Service (PaaS) – IBM Bluemix™ Within that framework, my current technology adventure is with Apache Spark, lightning fast cluster computing, for Big Data analytics. I’ve travelled the world and enjoy experiencing new ideas. Curiosity keeps me creating and consuming. “If it can be, I will try” – Me