Posted by: admin 3 weeks, 3 days ago (Comments) Zkomp is a light weight command line archive manager for all Linux distros. Create archives. Extract files from archive. How to use ? Zkomp is very ease to use. Download the zkomp Extract it and goto zkomp folder run ./zkomp –help usage: ./zkomp [OPTIONS] OPTIONS: -s –source: Input […]
Mezzanine: Adding recent post in home page
Posted by: admin 2 weeks, 3 days ago (Comments) Mezzanine is a powerful, consistent, and flexible content management platform. Built using the Django framework, Mezzanine provides a simple yet highly extensible architecture that encourages diving in and hacking on the code. To display the recent post in home page, Just copy and paste the below code in […]
Open Source Projects In Atlanta
A few times recently, I’ve been working with an open source project of some kind and it turned out that the maintainer was another Atlanta local. We have great resources for keeping track of what entrepreneurs in town are working on (see my post on that here), and what local VCs are up to (here), […]
Bayesian Networks vs. Petersburg
A couple of weeks ago we walked through how petersburg represents complex decisions (check it out here). Some of you may have recognized a familiar concept in that description: Bayesian networks (or bayesnet). Just like petersburg’s structure, a Bayesian network is at it’s core a Directed Acyclic Graph (DAG). So let’s first discuss what a […]
Thinking like a graph to make decisions: petersburg
A while back I posted an example outlining how to use petersburg to simulate the St. Petersburg Paradox. In this post, I’d like to dig a little deeper into what petersbug is and what it does. Petersburg is a minimal python library for representing complex decisions (as in decision theory decisions) as probabilistic graphs. With […]
Six ways to reverse pandas dataframe
In this post we will learn how to reverse pandas dataframe. We start by changing the first column with the last column and continue with reversing the order completely. After we have learned how to do that we continue by reversing the order of the rows. That is, pandas data frame can be reversed such […]
Development and Deployment of Cookiecutter-Django on Fedora
Last time we set up a Django Project using Cookiecutter, managed the application environment via Docker, and then deployed the app to Digital Ocean. In this tutorial, we’ll shift away from Docker and detail a development to deployment workflow of a Cookiecutter-Django Project on Fedora 23. Development Install cookiecutter globally and then generate a bootstrapped […]
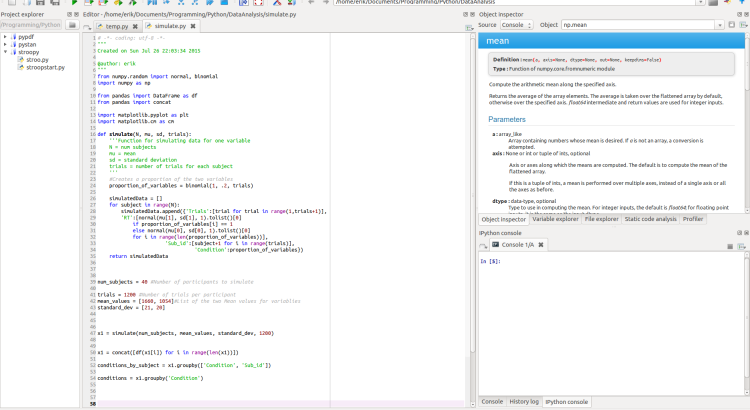
Why Spyder is the Best Python IDE for Science
Spyder is the best IDE that I have tested so far for doing data analysis, but also for plain programming. In this post I will start to briefly describe the IDE. Following the description of this top IDE the text will continue with a discussion of my favourite features. You will also find out how […]
NetBSD support for psutil
Roughly two months have passed since I last announced psutil added support for OpenBSD platforms. Today I am happy to announce we also have NetBSD support! This was contributed by Thomas Klausner, Ryo Onodera and myself in PR #570. Differences with FreeBSD (and OpenBSD) NetBSD implementation has similar limitations as the ones I encountered with OpenBSD. Again, […]

Non-coding tips a coder should know (w/memes!)
If you are anything like us, coding is what you love the most. But you also know there are many different aspects to be aware of beside coding that are important parts of a healthy development process. When you work as a developer you usually face clients or stakeholders that expect results and part of your job […]
WSGI: The Server-Application Interface for Python
Nowadays, almost all Python frameworks use WSGI as a means, if not the only means, to communicate with their web servers. This is how Django, Flask and many other popular frameworks do it. This article intends to provide the reader with a glimpse into how WSGI works, and allow the reader to build a simple […]

Behind the paper: Are visibility-derived AOT estimates suitable for parameterising satellite data atmospheric correction algorithms?
This has been a bit slow coming, but I am now sticking to my promise to write a Behind the paper post for each of my published academic papers. This is about: Wilson, R. T., E. J. Milton, and J. M. Nield (2015). Are visibility-derived AOT estimates suitable for parameterising satellite data atmospheric correction algorithms? International Journal of Remote […]
What is Model-Based Machine Learning?
About Tom: Tom Diethe is a research fellow on the SPHERE project at the University of Bristol. His research interests include probabilistic machine learning, computational statistics, learning theory, and data fusion. He has a PhD in machine learning applied to multivariate signal processing from University College London. Contact him at tom.diethe@bristol.ac.uk. Introduction If you haven’t […]
Unleashing Exploration on Enterprise Data
Enterprise customers have huge investments in transactional data systems, yet they struggle to provide their users with flexible and timely exploratory access to this data. One solution to this problem is to empower these users with the ability to use Jupyter Notebooks and Apache Spark running natively on z/OS to federate analytics across business critical […]

Managing Secrets at Scale at Velocity EU
UPDATE, 1/12/16 Our own Alex Schoof spoke at Velocity EU 2015 in Amsterdam on managing secrets at scale in the cloud. It was a highly rated talk that earned a write-up in InfoQ. Alex will be presenting this talk at tonight’s DevOps DC Meetup in Arlington, VA. You can view the slides from his talk […]