In this tutorial we will learn how to work with Excel files and Python. It will provide an overview of how to use Pandas to load and write these spreadsheets to Excel. In the first section, we will go through, with examples, how to read an Excel file, how to read specific columns from a spreadsheet, how to read multiple spreadsheets and combine them to one dataframe, how to read many Excel files, and, finally, how to convert data according to specific datatypes (e.g., using Pandas dtypes). When we have done this, we will continue by learning how to write Excel files; how to name the sheets and how to write to multiple sheets.
How to Install Pandas
Before we continue with this read and write Excel files tutorial there is something we need to do; installing Pandas (and Python, of course, if it’s not installed). We can install Pandas using Pip, given that we have Pip installed, that is. See here how to install pip.
# Linux Users pip install pandas # Windows Users python pip install pandas
Installing Anaconda Scientific Python Distribution
Another great option is to consider is to install the Anaconda Python distribution. This is really an easy and fast way to get started with computer science. No need to worry about installing the packages you need to do computer science separately.
Both of the above methods are explained in this tutorial.
How to Read Excel Files to Pandas Dataframes:
In this section we are going to learn how to read Excel files and spreadsheets to Pandas dataframe objects. All examples in this Pandas Excel tutorial use local files. Note, that read_excel also can also load Excel files from a URL to a dataframe. As always when working with Pandas, we have to start by importing the module:
import pandas as pd
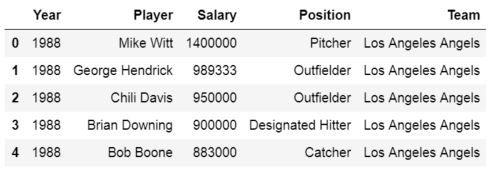
Now it’s time to learn how to use Pandas read_excel to read in data from an Excel file. The easiest way to use this method is to pass the file name as a string. If we don’t pass any other parameters, such as sheet name, it will read the first sheet in the index. In the first example we are not going to use any parameters:
df = pd.read_excel('MLBPlayerSalaries.xlsx')
df.head()
 Here, Pandas read_excel method read the data from the Excel file into a Pandas dataframe object. We then stored this dataframe into a variable called df.
Here, Pandas read_excel method read the data from the Excel file into a Pandas dataframe object. We then stored this dataframe into a variable called df.
When using read_excel Pandas will, by default, assign a numeric index or row label to the dataframe, and as usual when int comes to Python, the index will start with zero. We may have a reason to leave the default index as it is. For instance, if your data doesn’t have a column with unique values that can serve as a better index. In case there is a column that would serve as a better index, we can override the default behavior .
This is done by setting the index_col parameter to a column. It takes a numeric value for setting a single column as index or a list of numeric values for creating a multi-index. In the example below we use the column ‘Player’ as indices. Note, these are not unique and it may, thus, not make sense to use these values as indices.
df = pd.read_excel('MLBPlayerSalaries.xlsx', sheet_names='MLBPlayerSalaries', index_col='Player')
Reading Specific Columns using read_excel
When using Pandas read_excel we will automatically get all columns from an Excel files. If we, for some reason, don’t want to parse all columns in the Excel file, we can use the parameter usecols. Let’s say we want to create a dataframe with the columns Player, Salary, and Position, only. We can do this by adding 1, 3, and 4 in a list:
cols = [1, 2, 3]
df = pd.read_excel('MLBPlayerSalaries.xlsx', sheet_names='MLBPlayerSalaries', usecols=cols)
df.head()

According to the read_excel documentation we should be able to put in a string. For instance, cols=’Player:Position’ should give us the same results as above.
Missing Data
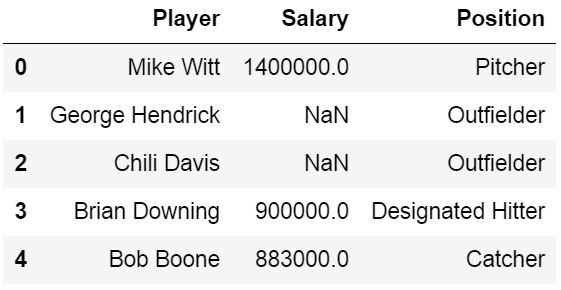
If our data has missing values in some cells and these missing values are coded in some way, like “Missing” we can use the na_values parameter. 
Pandas Read Excel Example with Missing Data
In the example below we are using the parameter na_values and we ar putting in a string (i.e., “Missing’):
df = pd.read_excel('MLBPlayerSalaries_MD.xlsx', na_values="Missing", sheet_names='MLBPlayerSalaries', usecols=cols)
df.head()
In in the read excel examples above we used a dataset that can be downloaded from this page.
- Read the post Data manipulation with Pandas for three methods on data manipulation of dataframes, including missing data.
How to Skip Rows when Reading an Excel File
Now we will learn how to skip rows when loading an Excel file using Pandas. For this read excel example we will use data that can be downloaded here.
In this example we read the sheet ‘session1’ which contains rows that we need to skip. These rows contains some information about the dataset: We will use the parameters sheet_name=’Session1′ to read the sheet named ‘Session1’. Note, the first sheet will be read if we don’t use the sheet_name parameter. In this example the important part is the parameter skiprow=2. We use this to skip the first two rows:
We will use the parameters sheet_name=’Session1′ to read the sheet named ‘Session1’. Note, the first sheet will be read if we don’t use the sheet_name parameter. In this example the important part is the parameter skiprow=2. We use this to skip the first two rows:
df = pd.read_excel('example_sheets1.xlsx', sheet_name='Session1', skiprows=2)
df.head()

We can obtain the same results as above using the header parameter. In the example Excel file, we use here, the third row contains the headers and we will use the parameter header=2 to tell Pandas read_excel that our headers are on the third row.
df = pd.read_excel('example_sheets1.xlsx', sheet_name='Session1', header=2)
Reading Multiple Excel Sheets to Pandas Dataframes
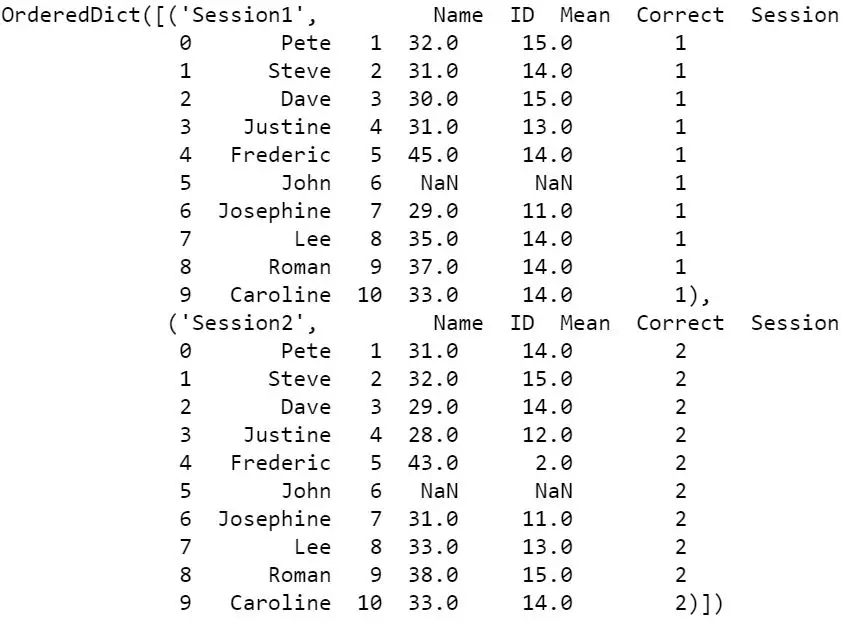
Our Excel file, example_sheets1.xlsx’, has two sheets: ‘Session1’, and ‘Session2.’ Each sheet has data for from an imagined experimental session. In the next example we are going to read both sheets, ‘Session1’ and ‘Session2’. Here’s how to use Pandas read_excel with multiple sheets:
df = pd.read_excel('example_sheets1.xlsx', sheet_name=['Session1', 'Session2'], skiprows=2)
By using the parameter sheet_name, and a list of names, we will get an ordered dictionary containing two dataframes:
df
Maybe we want to join the data from all sheets (in this case sessions). Merging Pandas dataframes are quite easy. We just use the concat function and loop over the keys (i.e., sheets):
df2 = pd.concat(df[frame] for frame in data.keys())
Now in the example Excel file there is a column identifying the dataset (e.g., session number). However, maybe we don’t have that kind of information in our Excel file. To merge the two dataframes and adding a column depicting which session we can use a for loop:
dfs = []
for framename in data.keys():
temp_df = data[framename]
temp_df['Session'] = framename
dfs.append(temp_df)
df = pd.concat(dfs)
In the code above we start by creating a list and continue by looping through the keys in the list of dataframes. Finally, we create a temporary dataframe and take the sheet name and add it in the column ‘Session’.
Pandas Read Excel all Sheets
If we want to use read_excel to load all sheets from an Excel file to a dataframe it is, of ourse, possible. We can set the parameter sheet_name to None.
all_sheets_df = pd.read_excel('example_sheets1.xlsx', sheet_name=None)
Reading Many Excel Files
In this section we will learn how to load many files into a Pandas dataframe because, in some cases, we may have a lot of Excel files containing data from, let’s say, different experiments. In Python we can use the modules os and fnmatch to read all files in a directory. Finally, we use list comprehension to use read_excel on all files we found:
import os, fnmatch
xlsx_files = fnmatch.filter(os.listdir('.'), '*concat*.xlsx')
dfs = [pd.read_excel(xlsx_file) for xlsx_file in xlsx_files]
If it makes sense we can, again, use the function concat to merge the dataframes:
df = pd.concat(dfs, sort=False)
There are other methods to reading many Excel files and merging them. We can, for instance, use the module glob:
import glob
list_of_xlsx = glob.glob('./*concat*.xlsx')
df = pdf.concat(list_of_xlsx)
Setting the Data type for data or columns
We can also, if we like, set the data type for the columns. Let’s read the example_sheets1.xlsx again. In the Pandas read_excel example below we use the dtype parameter to set the data type of some of the columns.
df = pd.read_excel('example_sheets1.xlsx',sheet_name='Session1',
header=1,dtype={'Names':str,'ID':str,
'Mean':int, 'Session':str})
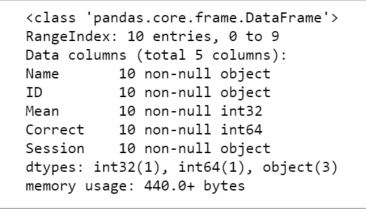
We can use the method info to see the what data types the different columns have:
df.info()
Writing Pandas Dataframes to Excel
Excel files can, of course, be created in Python using the module Pandas. In this section of the post we will learn how to create an excel file using Pandas. We will start by creating a dataframe with some variables but first we start by importing the modules Pandas:
import pandas as pd
The next step is to create the dataframe. We will create the dataframe using a dictionary. The keys will be the column names and the values will be lists containing our data:
df = pd.DataFrame({'Names':['Andreas', 'George', 'Steve',
'Sarah', 'Joanna', 'Hanna'],
'Age':[21, 22, 20, 19, 18, 23]})
Then we write the dataframe to an Excel file using the *to_excel* method. In the Pandas to_excel example below we don’t use any parameters.
df.to_excel('NamesAndAges.xlsx')
In the output below the effect of not using any parameters is evident. If we don’t use the parameter sheet_name we get the default sheet name, ‘Sheet1’. We can also see that we get a new column in our Excel file containing numbers. These are the indices from the dataframe.

If we want our sheet to be named something else and we don’t want the index column we can do like this:
df.to_excel('NamesAndAges.xlsx', sheet_name='Names and Ages', index=False)
Writing Multiple Pandas Dataframes to an Excel File:
If we happen to have many dataframes that we want to store in one Excel file but on different sheets we can do this easily. However, we need to use ExcelWriter now:
df1 = pd.DataFrame({'Names': ['Andreas', 'George', 'Steve',
'Sarah', 'Joanna', 'Hanna'],
'Age':[21, 22, 20, 19, 18, 23]})
df2 = pd.DataFrame({'Names': ['Pete', 'Jordan', 'Gustaf',
'Sophie', 'Sally', 'Simone'],
'Age':[22, 21, 19, 19, 29, 21]})
df3 = pd.DataFrame({'Names': ['Ulrich', 'Donald', 'Jon',
'Jessica', 'Elisabeth', 'Diana'],
'Age':[21, 21, 20, 19, 19, 22]})
dfs = {'Group1':df1, 'Group2':df2, 'Group3':df3}
writer = pd.ExcelWriter('NamesAndAges.xlsx', engine='xlsxwriter')
for sheet_name in dfs.keys():
dfs[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()
In the code above we create 3 dataframes and then we continue to put them in a dictionary. Note, the keys are the sheet names and the cell names are the dataframes. After this is done we create a writer object using the xlsxwriter engine. We then continue by looping through the keys (i.e., sheet names) and add each sheet. Finally, the file is saved. This is important as leaving this out will not give you the intended results.
Summary: How to Work Excel Files using Pandas
That was it! In this post we have learned a lot! We have, among other things, learned how to:
- Read Excel files and Spreadsheets using read_excel
- Load Excel files to dataframes:
- Read Excel sheets and skip rows
- Merging many sheets to a dataframe
- Loading many Excel files into one dataframe
- Load Excel files to dataframes:
- Write a dataframe to an Excel file
- Taking many dataframes and writing them to one Excel file with many sheets
Leave a comment below if you have any requests or suggestions on what should be covered next! Check the post A Basic Pandas Dataframe Tutorial for Beginners to learn more about working with Pandas dataframe. That is, after you have loaded them from a file (e.g., Excel spreadsheets)
The post Pandas Excel Tutorial: How to Read and Write Excel files appeared first on Erik Marsja.