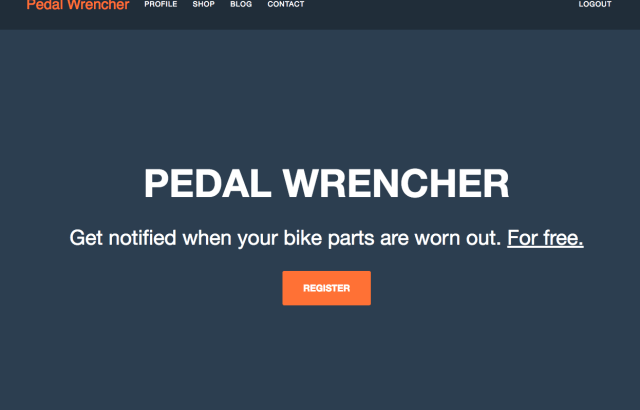
In the past I’ve posted a few times about the creation and stagnation of a project of mine, pedal wrencher. In recent months I’ve taken a more structured approach to iteratively improving the app and the plan is to share the lessons learned along the way a bit more freely going forward. This is a […]
Author: Will McGinnis
Data Science Things Roundup #5
Time again for the 5th edition of the data science things roundup, named suspiciously similarly to the much more established Data Science Roundup by RJ Metrics (but we won’t worry about that this week). In previous weeks we’ve seen some pretty cool ML and Data Science libraries, mostly in python, this week we branch out […]
Data Science Things Roundup #4
Time for another edition of the data science things roundup, where I round up some data science things for ya’ll. Todays collections are uncharacteristically R heavy. It’s usually pretty python and machine learning heavy, so if you find something you like here, be sure to check out previous editions as well. Without further adieu: Scikit-Learn […]

When do I work on what?
In past posts, I’ve shown that it’s pretty easy to create organization wide punchcards with git-pandas. Today, I put together a little twist on that particular visualization, to split my projects into two cohorts: open and closed source. My work at Predikto is, as work tends to be, mostly closed source (though we try to […]
Data Science Things Roundup #3
Time again for the 3rd edition of the data science things roundup, where I share a few data science things I’ve come across recently. Check out previous editions here and here. Self Organizing Maps with TensorFlow Google’s open sourcing of TensorFlow late last year caused a pretty big splash in the machine learning and data […]
Data Science Things Roundup #2
This is the second edition of the now-regular series of posts: Data Science Things Roundup, where I round up data science things (as you’d probably guessed). Last week we had a scikit-learn extension, a GUI framework for python CLIs and some writing about how kaggle winners won their competitions. This week is a bit more […]
Estimating the time spent on a project with git-pandas
I stumbled across a conversation recently on the Tech404 slack channel (a pretty good public slack group for Atlanta area software folks) about mostly taxes, but nestled in the middle was this project: git_time_extractor. In the past I’ve noticed a kind of weird concentration of git related open source projects among Atlanta developers, I’m not […]
Data Science Things Roundup #1
This is the first in a new series of posts, tailored more towards the newsletter subscribers (join it here). There are a few of these around the internet that I like, notably: ds_ldn’s Data Machina RJMetrics’ Data Science Roundup Jeremy Singer-Vine’s Data is Plural Mine will probably be way less consistent, so if you like […]
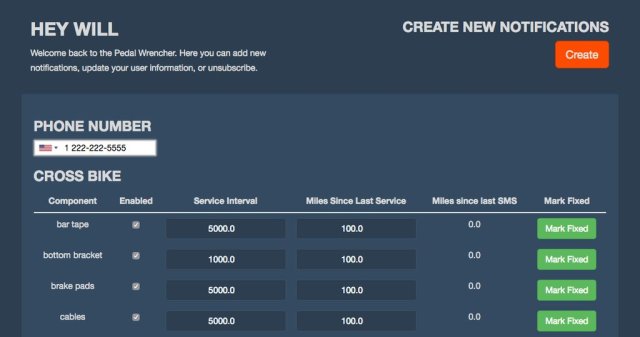
Projects Update: April 2016
Over the past year or so I’ve made a conscious effort to put out more public facing work through this site, some side projects and through github. Now, as a few have started to mature and take shape, I wanted to do the first of what will become an occasionally recurring kind of post: projects […]
Testing with Apache Spark and Python
Apache spark and pyspark in particular are fantastically powerful frameworks for large scale data processing and analytics. In the past I’ve written about flink’s python api a couple of times, but my day-to-day work is in pyspark, not flink. With any data processing pipeline, thorough testing is critical to ensuring veracity of the end-result, so […]
A (really) minimal static website generator with python and jinja2
From time to time I throw together a static HTML site for something and love how easy it is to just upload the files to s3 and have a fast site with pretty much no cost or work involved. For single-page sites in particular, this is pretty near painless, but as you start to get […]
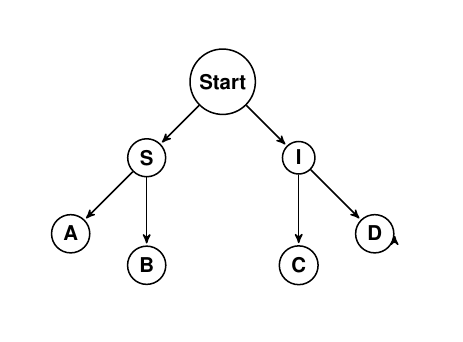
Simple estimation of hierarchical events with petersburg
So far the petersburg project has been primarily focused on static modeling of complex decisions with uncertainty. The longer-term goal is for it to to be a fully-feature toolbox for supporting such decisions. In that context, I’ve posted previously about: Decision strategies How the petersburg framework works How petersburg differs from bayesian networks And more. […]
Pypi-publisher: a simple cli for publishing python libraries
I’ve just finished the first release of pypi-publisher (ppp), a library for simple command line publishing of python libraries. You can grab the source or an install here: https://github.com/wdm0006/pypi-publisher In previous posts, I’ve shown how with a cookiecutter framework and some fast typing, you can release a package to pypi in pretty much no […]
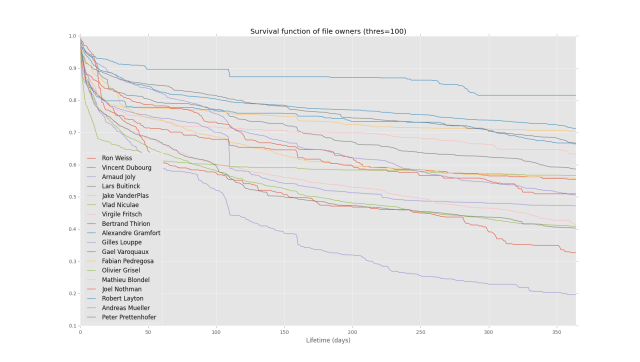
Using survival analysis and git-pandas to estimate code quality
Survival analysis is a statistical technique for determining the likelihood of events to happen over a timeline. It was originally based heavily in the medical/actuarial profession, where it would answer questions like: given this set of conditions, how likely is a person to survive X years? In previous posts, we’ve seen that we can tap […]
Journalism and the perfect pitch deck
Having been pretty immersed in the VC funded startup experience at Predikto for a couple of years now, I have (counter to what I would have ever thought), taken an intellectual curiosity to pitch decks. As I come across them, I put up notable pitch decks on a page here, including the fantastically annotated LinkedIn […]