The data science life cycle is generally comprised of the following components: data retrieval data cleaning data exploration and visualization statistical or predictive modeling While these components are helpful for understanding the different phases, they don’t help us think about our programming workflow. Often, the entire data science life cycle ends up as an arbitrary […]
Category: Statistics
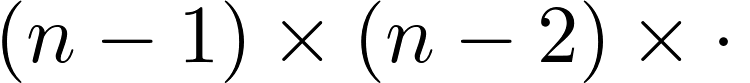
Itertools in Python 3, By Example
It has been called a “gem” and “pretty much the coolest thing ever,” and if you have not heard of it, then you are missing out on one of the greatest corners of the Python 3 standard library: itertools. A handful of excellent resources exist for learning what functions are available in the itertools module. […]

Data Retrieval and Cleaning: Tracking Migratory Patterns
Advancing your skills is an important part of being a data scientist. When starting out, you mostly focus on learning a programming language, proper use of third party tools, displaying visualizations, and the theoretical understanding of statistical algorithms. The next step is to test your skills on more difficult data sets. Sometimes these data sets […]
Introduction to Python 3
Python is a high-level, interpreted scripting language developed in the late 1980s by Guido van Rossum at the National Research Institute for Mathematics and Computer Science in the Netherlands. The initial version was published at the alt.sources newsgroup in 1991, and version 1.0 was released in 1994. Python 2.0 was released in 2000, and the […]
Regression of a Proportion in Python
I frequently predict proportions (e.g., proportion of year during which a customer is active). This is a regression task because the dependent variables is a float, but the dependent variable is bound between the 0 and 1. Googling around, I had a hard time finding the a good way to model this situation, so I’ve […]
Blogroll
I really enjoy reading blogs. That seems to be a slightly outdated view, as many people have moved over to using Twitter exclusively, but I like being able to follow everything that a specific person writes, and seeing mostly long-form articles rather than off-the-cuff comments. Back in the day, when blogs were really popular, every […]
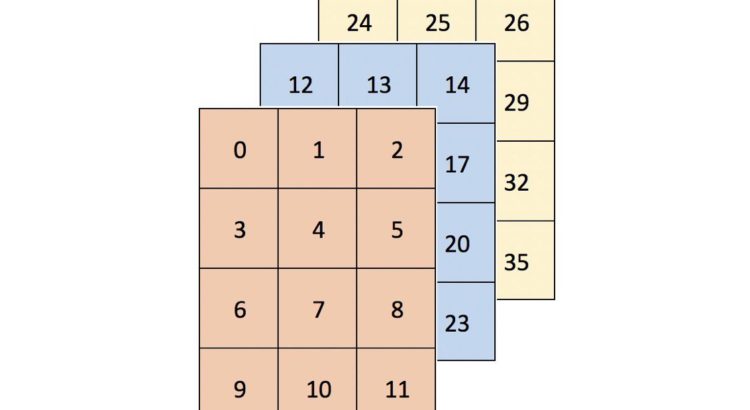
Look Ma, No For-Loops: Array Programming With NumPy
It is sometimes said that Python, compared to low-level languages such as C++, improves development time at the expense of runtime. Fortunately, there are a handful of ways to speed up operation runtime in Python without sacrificing ease of use. One option suited for fast numerical operations is NumPy, which deservedly bills itself as the […]
The Ultimate Guide To Speech Recognition With Python
Have you ever wondered how to add speech recognition to your Python project? If so, then keep reading! It’s easier than you might think. Far from a being a fad, the overwhelming success of speech-enabled products like Amazon Alexa has proven that some degree of speech support will be an essential aspect of household tech […]
Python Plotting With Matplotlib (Guide)
A picture says a thousand words, and with Python’s matplotlib library, it fortunately takes far less than a thousand words of code to create a production-quality graphic. However, matplotlib is also a massive library, and getting a plot to look “just right” is often practiced on a trial-and-error basis. Using one-liners to generate basic plots […]
Practical Introduction to Web Scraping in Python
Web Scraping Basics What is web scraping all about? Consider the following scenario: Imagine that one day, out of the blue, you find yourself thinking “Gee, I wonder who the five most popular mathematicians are?” You do a bit of thinking, and you get the idea to use Wikipedia’s XTools to measure the popularity of […]
Introduction to Python Ensembles
Stacking models in Python efficiently Ensembles have rapidly become one of the hottest and most popular methods in applied machine learning. Virtually every winning Kaggle solution features them, and many data science pipelines have ensembles in them. Put simply, ensembles combine predictions from different models to generate a final prediction, and the more models we […]

Learning Curves for Machine Learning
Diagnose Bias and Variance to Reduce Error When building machine learning models, we want to keep error as low as possible. Two major sources of error are bias and variance. If we managed to reduce these two, then we could build more accurate models. But how do we diagnose bias and variance in the first […]

Will’s Noise
Will’s NoiseBowl Game Pick ’em ResultsOn taking things too seriously: holiday editionElote: a python package of rating systemsRipyr: sampled metrics on datasets using python’s asyncioCategory Encoders v1.2.5 ReleaseStanding Peachtree ParkData Science Things Roudup #11Modernizing Pedalwrencher: whatever that means.Git-pandas caching for faster analysisCategory Encoders v1.2.4 Release http://www.willmcginnis.com Data Science, Technology, Atlanta Mon, 25 Dec 2017 00:52:27 […]

Pandas Concatenation Tutorial
You’d be hard pressed to find a data science project which doesn’t require multiple data sources to be combined together. Often times, data analysis calls for appending new rows to a table, pulling additional columns in, or in more complex cases, merging distinct tables on a common key. All of these tricks are handy to […]
Building a Simple Web App with Bottle, SQLAlchemy, and the Twitter API
This is a guest blog post by Bob Belderbos. Bob is a driven Pythonista working as a software developer at Oracle. He is also co-founder of PyBites, a Python blog featuring code challenges, articles, and news. Bob is passionate about automation, data, web development, code quality, and mentoring other developers. Last October we challenged our […]