
 Many enterprises are faced with the need to expand data processing access to users without impacting mission-critical transactional application environments. The trending approach to this problem is to move the data from these systems of record to a data warehouse. Moving data-at-rest to a mirrored data repository for analytics can yield costly side-effects such as expensive migration workloads, data concurrency and data security. Alternatively, the distillation of data-at-rest to isolate information of interest for downstream analytics can offer optimal results.
Many enterprises are faced with the need to expand data processing access to users without impacting mission-critical transactional application environments. The trending approach to this problem is to move the data from these systems of record to a data warehouse. Moving data-at-rest to a mirrored data repository for analytics can yield costly side-effects such as expensive migration workloads, data concurrency and data security. Alternatively, the distillation of data-at-rest to isolate information of interest for downstream analytics can offer optimal results.
IBM Announces
Today, IBM announced the release of the IBM z/OS Platform for Apache Spark. This enterprise-grade, native z/OS distribution of the open source in-memory analytics engine, enables the analyzing of business-critical z/OS data sources (such as DB2, IMS, VSAM and Adabas, among others) in place — with no data movement.
Designed to simplify the analysis of big data, this no-charge product allows enterprises to ingest data from diverse sources, including systems of record on the z/OS platform, and apply fast and federated large-scale data processing analytics using consistent Apache Spark APIs. By co-locating the data with the distillation and analysis jobs, companies can improve the time to value for actionable insights in a non-intrusive and cost effective manner.
 GitHub Tools
GitHub Tools
In conjunction with this product announcement, IBM has created a new GitHub organization to promote the development of an ecosystem of tools around Spark on z/OS. IBM has seeded the new organization with two GitHub repositories derived from Project Jupyter, namely the Scala Workbench and Interactive Insights Workbench. These tools are centered around a reference architecture that is aimed at bootstrapping data scientists who lack access to mainframe data stores.
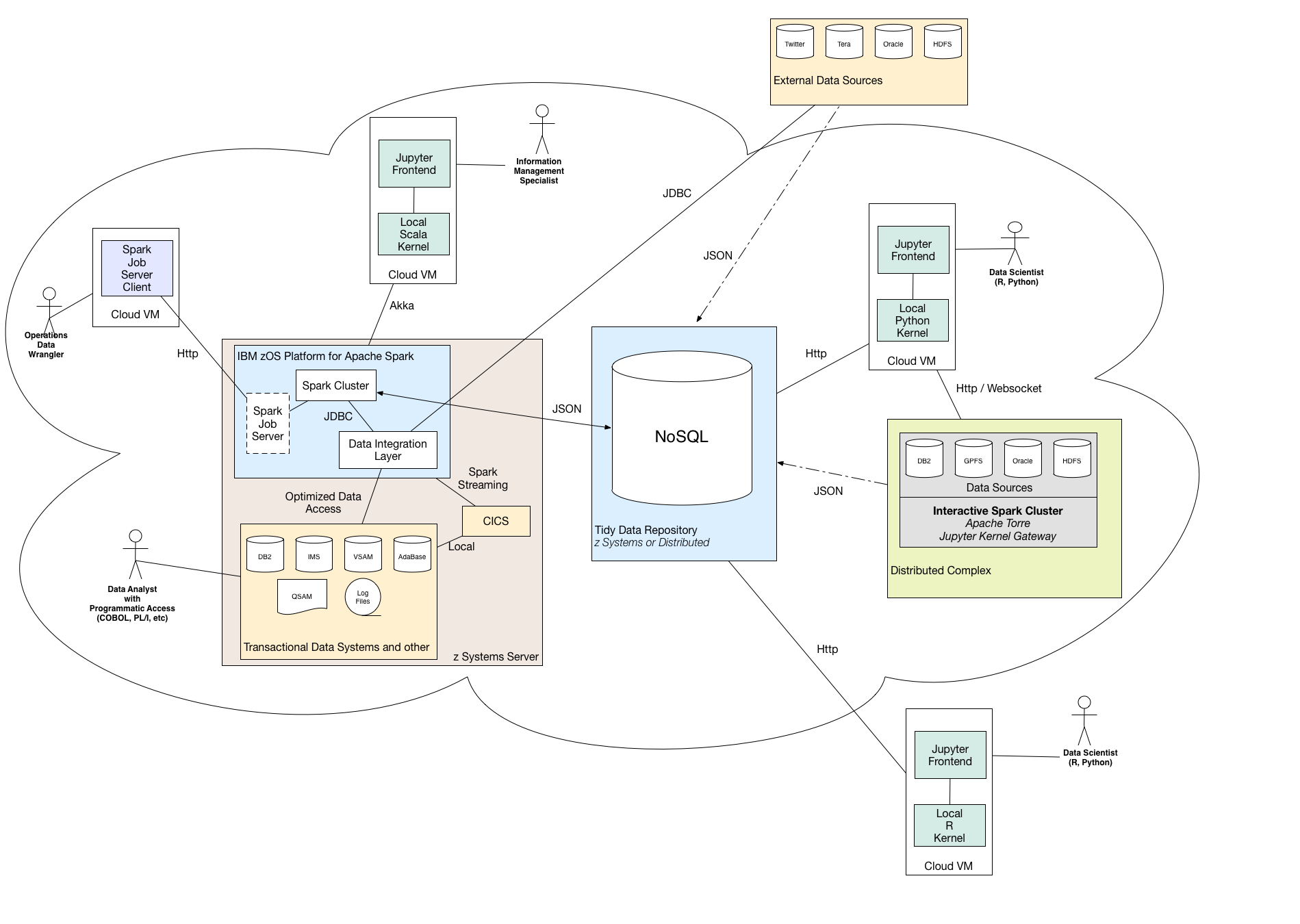
The data wrangler uses the z/OS Platform for Apache Spark to distill and analyze systems of record and then place the results into a NoSQL data repository, conforming to tidy data principles. With the complex task of munging multiple datasets already handled, data scientists can focus their energies on exploratory and predictive analytics using R or Python within a Jupyter notebook. This reference architecture offers a flexible, extensible, and interoperable solution for a variety of use cases. The open source Apache Spark distribution for z/OS, without data abstraction services, can be downloaded directly from DeveloperWorks and deployed using this installation guide.
Next Steps
The full package, including data abstraction, can be ordered at no-charge from Shopz. If you’re really interested in using Spark on the mainframe but feel that you need help getting
![]() started, Rocket Software is offering Launchpad, an engagement model designed to help you get your project ideas into production.
started, Rocket Software is offering Launchpad, an engagement model designed to help you get your project ideas into production.
Client-facing, strategy and development engineer responsible for architecting, implementing and running next-generation cloud applications on Bluemix, SoftLayer and private clouds.