Learning the basics of Python is a wonderful experience. But the euphoria of just learning can be replaced by the hunger for hands-on projects. It’s normal to want to build projects, hence the need for project ideas. The problem though is that some projects are either too simple for an intermediate Python developer or too […]
Category: Statistics

How to Learn Python for Data Science In 5 Steps
Why Learn Python For Data Science? Before we explore how to learn Python for data science, we should briefly answer why you should learn Python in the first place. In short, understanding Python is one of the valuable skills needed for a data science career. Though it hasn’t always been, Python is the programming language […]

The Ultimate List of Data Science Podcasts
Podcasts are a great way to immerse yourself in an industry, especially when it comes to data science. The field moves extremely quickly, and it can be difficult to keep up with all the new developments happening each week! Take advantage of those times in the day when your body is busy, but your mind […]

Data Science Project: Profitable App Profiles for App Store and Google Play
At Dataquest, we strongly advocate portfolio projects as a means of getting a first data science job. In this blog post, we’ll walk you through an example portfolio project. This is the third project in our Data Science Portfolio Project series: Is Fandango Still Inflating Ratings? Where to Advertise an E-learning Product Profitable App Profiles […]
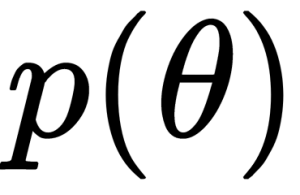
Probabilistic Programming in Python
Learn about probabilistic programming in this guest post by Osvaldo Martin, a researcher at The National Scientific and Technical Research Council (CONICET). Bayesian Inference Bayesian statistics is conceptually very simple; we have the knowns and the unknowns; we use Bayes’ theorem to condition the latter on the former. If we are lucky, this process will reduce the uncertainty about the unknowns. […]

The Ultimate Guide to Python Type Checking
In this guide, you will get a look into Python type checking. Traditionally, types have been handled by the Python interpreter in a flexible but implicit way. Recent versions of Python allow you to specify explicit type hints that can be used by different tools to help you develop your code more efficiently. In this […]

Python Pandas Groupby Tutorial
In this Pandas group by we are going to learn how to organize Pandas dataframes by groups. More specifically, we are going to learn how to group by one and multiple columns. Furthermore, we are going to learn how calculate some basics summary statistics (e.g., mean, median), convert Pandas groupby to dataframe, calculate the percentage of […]
Sending Emails With Python
You probably found this tutorial because you want to send emails using Python. Perhaps you want to receive email reminders from your code, send a confirmation email to users when they create an account, or send emails to members of your organization to remind them to pay their dues. Sending emails manually is a time-consuming […]
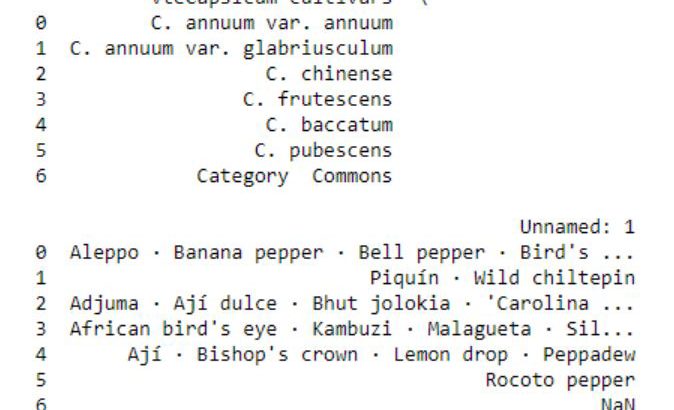
Explorative Data Analysis with Pandas, SciPy, and Seaborn
In this post we are going to learn to explore data using Python, Pandas, and Seaborn. The data we are going to explore is data from a Wikipedia article. In this post we are actually going to learn how to parse data from a URL, exploring this data by grouping it and data visualization. More […]
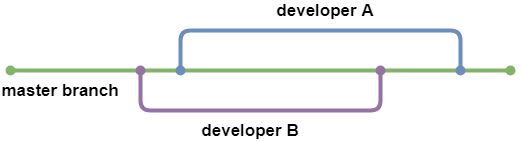
Continuous Integration with Python: An Introduction
When writing code on your own, the only priority is making it work. However, working in a team of professional software developers brings a plethora of challenges. One of those challenges is coordinating many people working on the same code. How do professional teams make dozens of changes per day while making sure everyone is […]

Interactive Data Visualization in Python With Bokeh
Bokeh prides itself on being a library for interactive data visualization. Unlike popular counterparts in the Python visualization space, like Matplotlib and Seaborn, Bokeh renders its graphics using HTML and JavaScript. This makes it a great candidate for building web-based dashboards and applications. However, it’s an equally powerful tool for exploring and understanding your data […]
How to use Pandas Sample to Select Rows and Columns
In this tutorial we will learn how to use Pandas sample to randomly select rows and columns from a Pandas dataframe. There are some reasons for randomly sample our data; for instance, we may have a very large dataset and want to build our models on a smaller sample of the data. Other examples are […]
Pandas Excel Tutorial: How to Read and Write Excel files
In this tutorial we will learn how to work with Excel files and Python. It will provide an overview of how to use Pandas to load and write these spreadsheets to Excel. In the first section, we will go through, with examples, how to read an Excel file, how to read specific columns from a […]
Data Manipulation with Pandas: A Brief Tutorial
Learn three data manipulation techniques with Pandas in this guest post by Harish Garg, a software developer and data analyst, and the author of Mastering Exploratory Analysis with pandas. Modifying a Pandas DataFrame Using the inplace Parameter In this section, you’ll learn how to modify a DataFrame using the inplace parameter. You’ll first read a real dataset into […]
Looking Towards the Future of Automated Machine-learning
I recently gave a presentation at Venture Cafe describing how I see automation changing python, machine-learning workflows in the near future. In this post, I highlight the presentation’s main points. You can find the slides here. From Ray Kurzweil’s excitement about a technological singularity to Elon Musk’s warnings about an A.I. Apocalypse, automated machine-learning evokes […]