
Prerequisites: Have the Selenium Python package working on your machine. See this guide for help.
If you ever find yourself doing something repetitive online, there’s probably a Python package that can help you automate the process. One that’s extremely simple to use and flashy to show off to others is called Selenium. Selenium basically allows you to program a browser to do anything by itself that you could do manually with mouse and keyboard. This can often result in huge time savings with relatively simple scripts, and when non-programmers see your browser operating by itself they’ll think you’re a programming jedi.
In this post, we’re going to write an easy Selenium script just to illustrate the basics of the process. Once you get the gist of it, check out the post next week for a more involved programming adventure. And if you don’t already have Selenium up and running take a look at this guide, it’ll take just a minute to set up.
To demonstrate Selenium’s usage, we’re going to get some urls from the search engine DuckDuckGo. Specifically, we are going to grab the urls on the initial results page of some query. You can imagine this being useful for quickly testing whether the search results for something you query a lot have changed without actually having to look over all the results yourself. (This isn’t actually the package I would recommend for performing that task, but this is just an introductory example before we get deeper into Selenium. And even if Selenium isn’t the most efficient way to do something, it’s often the flashiest, which can have its uses.)
First things first, let’s fire up Selenium.
from selenium import webdriver browser = webdriver.Chrome(executable_path="C:UsersgstantonDownloadschromedriver.exe") url = "https://www.duckduckgo.com" browser.get(url) browser.maximize_window()
Great, so we can navigate to DuckDuckGo. But how do we actually enter something into the search bar and get the results? For that, we will need some way to identify specific elements of the web page. If you know anything about HMTL and CSS, you know that HTML gives a webpage its structure, and CSS gives a webpage its style. We will need to know our way around these things just a little bit to be able to select just the elements we are interested in and perform operations on them. We’ll see this in practice by searching the term “rebellion” and grabbing the resulting urls.
If we want DuckDuckGo to perform a search for us, there are two things we need to use: the search bar, and the search button. We will first enter our search query into the search bar, and then initiate the search by clicking the button. But how do we identify these elements? Well, to examine the underlying structure of the webpage, we will use Chrome’s Developer Tools. And to actually refer to a given element in our code, we have two options: XPath and CSS Selectors. We won’t go into details, so just know that here we’ll be using XPath. CSS Selectors will be covered in a later post.
First, manually navigate to https://www.duckduckgo.com in Chrome. In the upper right corner, click on the menu dropdown (for me, it looks like three stacked gray dots). Go to “More tools”, and then select “Developer tools”. You should now see something like this:

The code there on the right in the upper half is the webpage’s HTML. You can click on the gray arrows next to elements to display and hide child elements, and then do the same with the child elements of those child elements, and so on.
Instead of laboriously looking through all the HTML code for something that looks like a search bar element, the developer tools provide a great tool for instantly selecting any element you want. Notice that when your cursor hovers over the HTML, different elements on the actual page are highlighted. We want to do the reverse of this, selecting page elements and having the corresponding HTML highlighted. To do this, click on the arrow shown here:
![]()
Now, when your cursor hovers over page elements, you should see the corresponding HTML elements highlighted on the right. Click on the search bar to select that element. On the right, you should now see an input tag highlighted. Notice that the input tag has an id attribute. We can refer to the search bar using this id like so: “//input[@id=’search_form_input_homepage’]”
Doing the same procedure for the search button, the Xpath expression should look like: “//input[@id=’search_button_homepage’]”
Now we can finally enter some text into the search bar, and then click the search button to view the results.
search_bar = browser.find_element_by_xpath("//input[@id='search_form_input_homepage']")
## also try the following line, a shorter, cleaner way when you're sure id's are unique
#search_bar = browser.find_element_by_id('search_form_input_homepage')
search_bar.send_keys("rebellion")
search_button = browser.find_element_by_xpath("//input[@id='search_button_homepage']")
#search_button = browser.find_element_by_id('search_button_homepage')
search_button.click()
This should get you to a page that looks something like this:
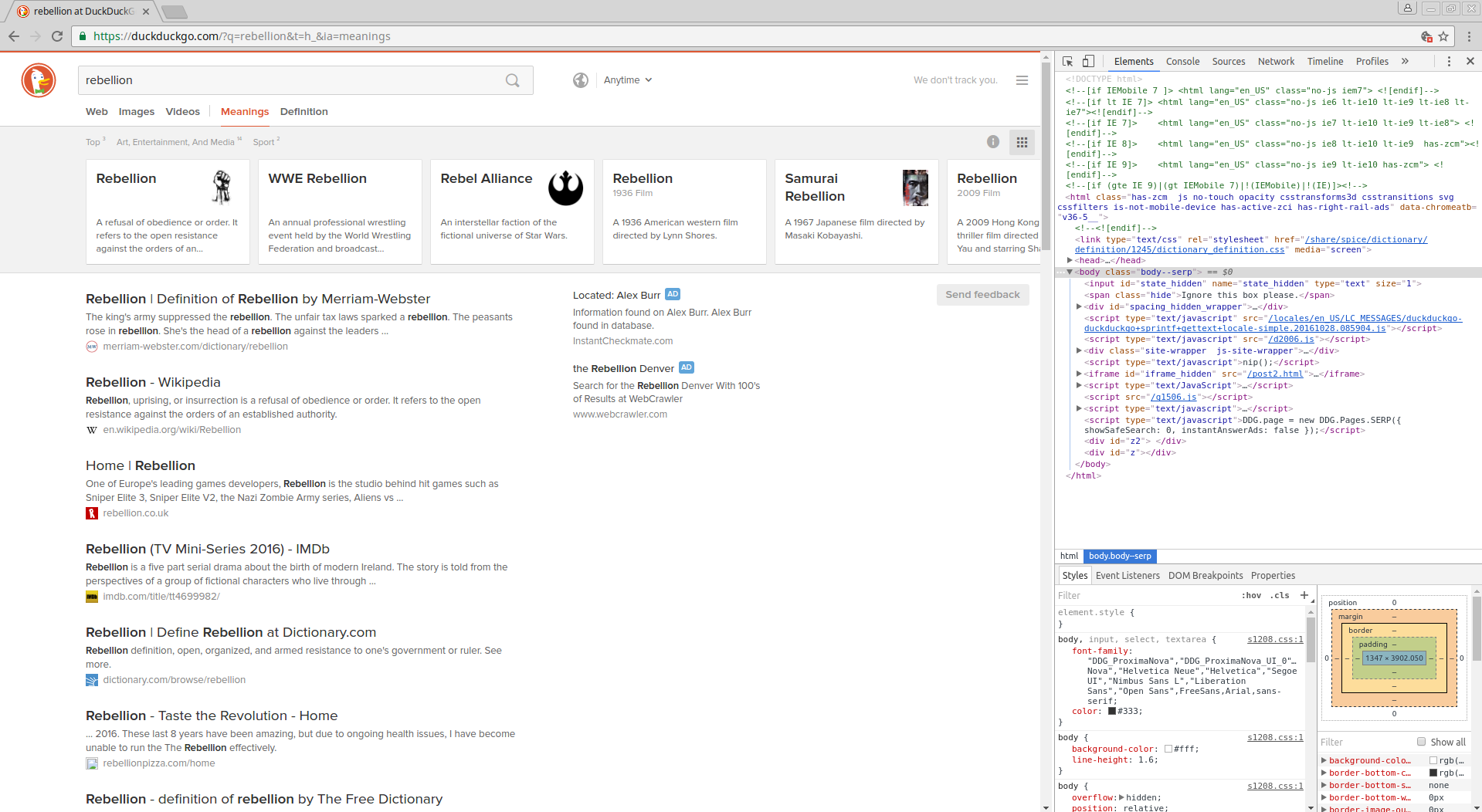
Okay, now we want to get the urls for each of the search results. Using our developer tools like before and selecting the heading of one of the search results, we find that the following XPath might be appropriate: “a[@class=’result__a’]”
Let’s try it out.
## get every result element
search_results = browser.find_elements_by_xpath("//a[@class='result__a']")
## check that we are grabbing correct elements
print(len(search_results))
for result in search_results:
print(result.text)
Comparing the DuckDuckGo search results page to what we just printed, it looks like we are indeed grabbing the search result elements. Now we just need to extract the urls from them.
## make a list of the url's
urls = []
for result in search_results:
urls.append(result.get_attribute("href"))
## print the url's to make sure they look correct
for url in urls:
print(url)
When I ran it, it looked like I picked up the urls for a couple of ads by mistake (they are the ones with the really long urls). If you want a challenge, see if you can figure out an XPath expression that excludes these ad urls. To see one way of doing it, check out the full script below.
Well, there you have it. The basic idea is to use your browser’s developer tools to come up with expressions to select the elements you want. But this is just a taste of what Selenium is capable of. Almost anything you can do yourself with mouse and keyboard can be simulated in Selenium. This makes Selenium a really helpful tool for automating online procedures where lots of clicks and text submissions and general Javascript interactivity are involved. And non-programmers are often extremely impressed by it. Later, we’ll explore how to get the most out of Selenium with some more complex applications. If you have any problems you’d like to see solved with Selenium, feel free to let me know in the comments or via email.
Here’s the full script:
from selenium import webdriver
browser = webdriver.Chrome(executable_path="C:UsersgstantonDownloadschromedriver.exe")
url = "https://www.duckduckgo.com"
browser.get(url)
browser.maximize_window()
search_bar = browser.find_element_by_xpath("//input[@id='search_form_input_homepage']")
search_bar.send_keys("rebellion")
search_button = browser.find_element_by_xpath("//input[@id='search_button_homepage']")
search_button.click()
#search_results = browser.find_elements_by_xpath("//a[@class='result__a']")
search_results = browser.find_elements_by_xpath("//div[@id='links']/div/div/h2/a[@class='result__a']")
print(len(search_results))
for result in search_results:
print(result.text)
urls = []
for result in search_results:
urls.append(result.get_attribute("href"))
for url in urls:
print(url)
browser.quit()