Fugue uses Python extensively throughout the Conductor and in our support tools, due to its ease-of-use, extensive package library, and powerful language tools. One thing we’ve learned from building complex software for the cloud is that a language is only as good as its debugging and profiling tools. Logic errors, CPU spikes, and memory leaks are inevitable, but a good debugger, CPU profiler, and memory profiler can make finding these errors significantly easier and faster, letting our developers get back to creating Fugue’s dynamic cloud orchestration and enforcement system. Let’s look at a case in point.
In the fall, our metrics reported that a Python component of Fugue called the reflector was experiencing random restarts and instability after a few days of uptime. Looking at memory usage showed that the reflector’s memory footprint increased monotonically and continuously, indicating a memory leak. tracemalloc, a powerful memory tracking tool in the Python standard library, made it possible to quickly diagnose and fix the leak. We discovered that the memory leak was related to our use of requests, a popular third-party Python HTTP library. Rewriting the component to use urllib from the Python standard library eliminated the memory leak. In this blog, we’ll explore the details.
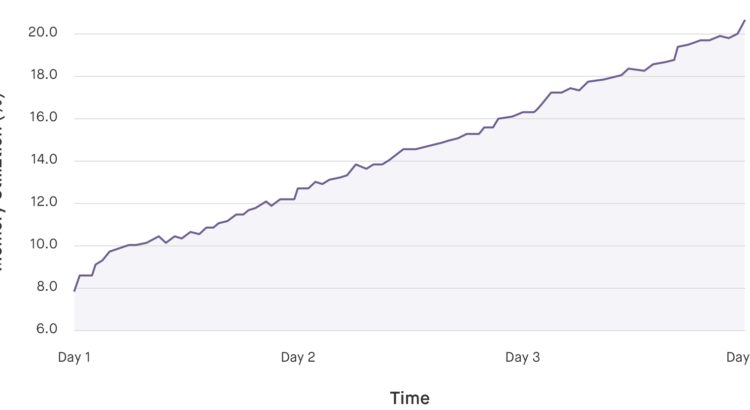
 Metrics show the problem: Percentage of total system memory used by the reflector, using the requests library.
Metrics show the problem: Percentage of total system memory used by the reflector, using the requests library.
Memory Allocation in Python
In most scenarios, there’s no need to understand memory management in Python beyond knowing that the interpreter manages memory for you. However, when writing large, complex Python programs with high stability requirements, it’s useful to peek behind the curtain to understand how to write code that interacts well with Python’s memory management algorithms. Notably, Python uses reference counting and garbage collection to free memory blocks, and only frees memory to the system when certain internal requirements are met. A pure Python script will never have direct control over memory allocation in the interpreter. If direct control over memory allocation is desired, the interpreter’s memory allocation can be bypassed by writing or using an extension. For example, numpy manages memory for large data arrays using its own memory allocator.
Fundamentally, Python is a garbage-collected language that uses reference counting. The interpreter automatically allocates memory for objects as they are created and tracks the number of references to those objects in a data structure associated with the object itself. This memory will be freed when the reference count for those objects reaches zero. In addition, garbage collection will detect cycles and remove objects that are only referenced in cycles. Every byte of memory allocated within the Python interpreter is able to be freed between these two mechanisms, but no claims can be made about memory allocated in extensions.
Python manages its own heap, separate from the system heap. Memory is allocated in the Python interpreter by different methods according to the type of the object to be created. Scalar types, such as integers and floats, use different memory allocation methods than composite types, such as lists, tuples, and dictionaries. In general, memory is allocated on the Python heap in fixed-size blocks, depending on the type. These blocks are organized into pools, which are further organized into arenas. Memory is pre-allocated using arenas, pools, and blocks, which are then used to store data as needed over the course of program’s execution. Since these blocks, pools, and arenas are kept in Python’s own heap, freeing a memory block merely marks it as available for future use in the interpreter. Freeing memory in Python does not immediately free the memory at the system level. When an entire arena is marked as free, its memory is released by the Python interpreter and returned to the system. However, this may occur infrequently due to memory fragmentation.
Due to these abstractions, memory usage in Python often exhibits high-water-mark behavior, where peak memory usage determines the memory usage for the remainder of execution, regardless of whether that memory is actively being used. Furthermore, the relationship between memory being “freed” in code and being returned to the system is vague and difficult to predict. These behaviors make completely understanding the memory usage of complex Python programs notoriously difficult.
Memory Profiling Using tracemalloc
tracemalloc is a package included in the Python standard library (as of version 3.4). It provides detailed, block-level traces of memory allocation, including the full traceback to the line where the memory allocation occurred, and statistics for the overall memory behavior of a program. The documentation is available here and provides a good introduction to its capabilities. The original Python Enhancement Proposal (PEP) introducing it also has some insight on its design.
tracemalloc can be used to locate high-memory-usage areas of code in two ways:
- looking at cumulative statistics on memory use to identify which object allocations are using the most memory, and
- tracing execution frames to identify where those objects are allocated in the code.
Module-level Memory Usage
We start by tracing the memory usage of the entire program, so we can identify, at a high level, which objects are using the most memory. This will hopefully provide us with enough insight to know where and how to look more deeply. The following wrapper starts tracing and prints statistics when Ctrl-C is hit:
import tracemalloc
tracemalloc.start(10)
try:
run_reflector()
except:
snapshot = tracemalloc.take_snapshot()
top_n(25, snapshot, trace_type='filename')
tracemalloc.start(10) starts memory tracing, while saving 10 frames of traceback for each entry. The default is 1, but saving more traceback frames is useful if you plan on using tracebacks to locate memory leaks, which will be discussed later. tracemalloc.take_snapshot() takes a snapshot of currently allocated memory in the Python heap. It stores the number of allocated blocks, their size, and tracebacks to identify which lines of code allocated which blocks of memory. Once a snapshot is created, we can compute statistics on memory use, compare snapshots, or save them to analyze later. top_n is a helper function I wrote to pretty print the output from tracemalloc. Here, I ask for the top 25 memory allocations in the snapshot, grouped by filename. After running for a few minutes, the output looks like this:
[ Top 25 with filename tracebacks ]
197618 blocks 17.02311134338379 MB
/Users/mike/.pyenv/versions/3.4.2/lib/python3.4/collections/__init__.py:0: size=17.0 MiB, count=197618, average=90 B
105364 blocks 11.34091567993164 MB
<frozen importlib._bootstrap>:0: size=11.3 MiB, count=105364, average=113 B
60339 blocks 9.233230590820312 MB
/Users/mike/.pyenv/versions/3.4.2/lib/python3.4/json/decoder.py:0: size=9455 KiB, count=60339, average=160 B
.
.
.
This shows the cumulative amount of memory allocated by the component over the entire runtime, grouped by filename. At this level of granularity, it’s hard to make sense of the results. For instance, the first line shows us that 17 MB of collections objects are created, but this view doesn’t provide enough detail for us to know which objects, or where they’re being used. A different approach is needed to isolate the problem.
Understanding tracemalloc Output
tracemalloc shows the net memory usage at the time a memory snapshot is taken. When comparing two snapshots, it shows the net memory usage between the two snapshots. If memory is allocated and freed between snapshots, it won’t be shown in the output. Therefore, if snapshots are created at the same point in a loop, any memory allocations visible in the differences between two snapshots are contributing to the long-term total amount of memory used, rather than being a temporary allocation made in the course of execution.
In the case of reference cycles that require garbage collection, uncollected cycles are recorded in the output, while collected cycles are not. Any blocks freed by the garbage collector in the time covered by a snapshot will be recorded as freed memory. Therefore, forcing garbage collection with gc.collect() before taking a snapshot will reduce noise in the output.
Per-Iteration Memory Usage
Since we’re looking for a memory leak, it’s useful to understand how the memory usage of our program changes over time. We can instrument the main loop of the component, to see how much memory is allocated in each iteration, by calling the following method from the main loop:
def collect_stats(self):
self.snapshots.append(tracemalloc.take_snapshot())
if len(self.snapshots) > 1:
stats = self.snapshots[-1].filter_traces(filters).compare_to(self.snapshots[-2], 'filename')
for stat in stats[:10]:
print("{} new KiB {} total KiB {} new {} total memory blocks: ".format(stat.size_diff/1024, stat.size / 1024, stat.count_diff ,stat.count))
for line in stat.traceback.format():
print(line)
This code takes a memory snapshot and saves it, then uses snapshot.compare_to(other_snapshot, group_by='filename') to compare the newest snapshot with the previous snapshot, with results grouped by filename. After a few iterations to warm up memory, the output looks like this:
[ Top 5 with filename tracebacks ]
190.7421875 new KiB 1356.5634765625 total KiB 1930 new 13574 total memory blocks: (1)
File "/Users/mike/.pyenv/versions/3.4.2/lib/python3.4/linecache.py", line 0
2.1328125 new KiB 12.375 total KiB 32 new 86 total memory blocks: (2)
File "/Users/mike/.pyenv/versions/3.4.2/lib/python3.4/tracemalloc.py", line 0
1.859375 new KiB 18.7001953125 total KiB 3 new 53 total memory blocks: (3)
File "/Users/mike/.pyenv/versions/venv/lib/python3.4/site-packages/requests/packages/urllib3/connection.py", line 0
-1.71875 new KiB 34.5224609375 total KiB -2 new 91 total memory blocks:
File "/Users/mike/.pyenv/versions/venv/lib/python3.4/site-packages/requests/packages/urllib3/connectionpool.py", line 0
1.66015625 new KiB 61.662109375 total KiB 18 new 260 total memory blocks:
File "/Users/mike/.pyenv/versions/3.4.2/lib/python3.4/urllib/parse.py", line 0
The linecache (1) and tracemalloc (2) allocations are part of the instrumentation, but we can also see some memory allocations made by the requests HTTP package (3) that warrant further investigation. Recall that tracemalloc tracks net memory usage, so these memory allocations are accumulating on each iteration. Although the individual allocations are small and don’t jump out as problematic, the memory leak only becomes apparent over the course of a few days, so it’s likely to be a case of small losses adding up.
Filtering Snapshots
Now that we have an idea of where to look, we can use tracemalloc’s filtering capabilities to show only memory allocations related to the requests package:
from tracemalloc import Filter
filters = [Filter(inclusive=True, filename_pattern="*requests*")]
filtered_stats = snapshot.filter_traces(filters).compare_to(old_snapshot.filter_traces(filters), 'traceback')
for stat in stats[:10]:
print("{} new KiB {} total KiB {} new {} total memory blocks: ".format(stat.size_diff/1024, stat.size / 1024, stat.count_diff ,stat.count))
for line in stat.traceback.format():
print(line)
snapshot.filter_traces() takes a list of Filters to apply to the snapshot. Here, we create a Filter in inclusive mode, so it includes only traces that match the filename_pattern. When inclusive is False, the filter excludes traces that match the filename_pattern. The filename_pattern uses UNIX-style wildcards to match filenames in the traceback. In this example, the wildcards in “requests” match occurrences of “requests” in the middle of a path, such as "/Users/mike/.pyenv/versions/venv/lib/python3.4/site-packages/requests/sessions.py".
We then use compare_to() to compare the results to the previous snapshot. The filtered output is below:
48.7890625 new KiB 373.974609375 total KiB 4 new 1440 total memory blocks: (4)
File "/Users/mike/.pyenv/versions/venv/lib/python3.4/site-packages/requests/structures.py", line 0
1.46875 new KiB 16.2939453125 total KiB 2 new 49 total memory blocks:
File "/Users/mike/.pyenv/versions/venv/lib/python3.4/site-packages/requests_unixsocket/__init__.py", line 0
-1.4453125 new KiB 34.2802734375 total KiB -2 new 96 total memory blocks: (5)
File "/Users/mike/.pyenv/versions/venv/lib/python3.4/site-packages/requests/sessions.py", line 0
-0.859375 new KiB 31.8505859375 total KiB -1 new 85 total memory blocks:
File "/Users/mike/.pyenv/versions/venv/lib/python3.4/site-packages/requests/packages/urllib3/connectionpool.py", line 0
0.6484375 new KiB 20.8330078125 total KiB 1 new 56 total memory blocks:
File "/Users/mike/.pyenv/versions/venv/lib/python3.4/site-packages/requests/packages/urllib3/connection.py", line 0
With the Filter in place, we can clearly see how requests is using memory. Line (4) shows that roughly 50 KiB of memory is lost in requests on each iteration of the main loop. Note that negative memory allocations, such as (5), are visible in this output. These allocations are freeing memory allocated in previous loop iterations.
Tracking Down Memory Allocations
To determine which uses of requests are leaking memory, we can take a detailed look at where problematic memory allocations occur by calling compare_to() with traceback instead of filename, while using a Filter to narrow down the output:
stats = snapshot.filter_traces(filters).compare_to(old_snapshot.filter_traces(filters), 'traceback')
This prints 10 frames of traceback (since we started tracing with tracemalloc.start(10)) for each entry in the output, a truncated example of which is below:
5 memory blocks: 4.4921875 KiB
File "/Users/mike/.pyenv/versions/venv/lib/python3.4/site-packages/requests/sessions.py", line 585
r = adapter.send(request, **kwargs)
File "/Users/mike/.pyenv/versions/venv/lib/python3.4/site-packages/requests/sessions.py", line 475
resp = self.send(prep, **send_kwargs)
File "/Users/mike/.pyenv/versions/venv/lib/python3.4/site-packages/requests_unixsocket/__init__.py", line 46
return session.request(method=method, url=url, **kwargs)
File "/Users/mike/.pyenv/versions/venv/lib/python3.4/site-packages/requests_unixsocket/__init__.py", line 60
return request('post', url, data=data, json=json, **kwargs)
The full traceback gives us the ability to trace backwards from memory allocations to the lines in our project code that generate them. In the case of this component, our uses of requests came from an internal storage library that used an HTTP API. Rewriting the library to use urllib directly eliminated the memory leak.
 Metrics indicate the problem is solved: Percentage of total system memory used by the reflector, after removing requests and switching to
Metrics indicate the problem is solved: Percentage of total system memory used by the reflector, after removing requests and switching to urllib.
Memory Profiling: Art or Science?
tracemalloc is a powerful tool for understanding the memory usage of Python programs. It helped us understand module-level memory usage, find out which objects are being allocated the most, and it demonstrated how the reflector’s memory usage changed on a per-iteration basis. It comes with useful filtering tools and gives us the ability to see the full traceback for any memory allocation. Despite all of its features, however, finding memory leaks in Python can still feel like more of an art than a science. Memory profilers give us the ability to see how memory is being used, but oftentimes it’s difficult to find the exact memory allocation that is causing problems. It’s up to us to synthesize the information we get from our tools into a conclusion about the memory behavior of the program, then make a decision about what actions to take from there.
We use virtually every available Python tool (test frameworks, cProfile, etc.) to make Fugue’s system reliable, performant, and easy to maintain. The broker and reflector both take advantage of Python’s introspection to make judgments about dynamic calls to the AWS API, which allows us to focus on logic rather than coding exhaustive cases. Fugue leverages the strengths of Python where it makes sense in the system, which ultimately means more product stability and extensibility for end-users.