In this Pandas tutorial we will learn how to work with Pandas dataframes. More specifically, we will learn how to read and write Excel (i.e., xlsx) and CSV files using Pandas.
We will also learn how to add a column to Pandas dataframe object, and how to remove a column. Finally, we will also learn how to subset and group our dataframe.
What is Pandas Dataframe?
Pandas is a library for enabling data analysis in Python. It’s very easy to use and quite similar to the programming language R’s data frames. It’s open source and free.
When working datasets from real experiments we need a method to group data of differing types. For instance, in psychology research we often use different data types. If you have experience in doing data analysis with SPSS you are probably familiar with some of them (e.g., categorical, ordinal, continuous).
Imagine that we have collected data in an experiment in which we were interested in how images of kittens and puppies affected the mood in the subjects and compared it to neutral images.
After each image, randomly presented on a computer screen, the subjects were to rate their mood on a scale.
Then the data might look like this:
| Condition | Mood Rating | Subject Number | Trial Number |
| Puppy | 7 | 1 | 1 |
| Kitten | 6 | 1 | 2 |
| Puppy | 7 | 1 | 4 |
| Neutral | 6 | 1 | 5 |
| … | … | … | … |
| Puppy | 6 | 12 | 9 |
| Neutral | 6 | 12 | 10 |
This is generally what a dataframe is. Obviously, working with Pandas dataframe will make working with our data easier. See here for more extensive information.
Pandas Create Dataframe
In Psychology, the most common methods to collect data is using questionnaires, experiment software (e.g., PsychoPy, OpenSesame), and observations.
When using digital applications for both questionnaires and experiment software we will, of course, also get our data in a digital file format (e.g., Excel spreadsheets and Comma-separated, CSV, files).
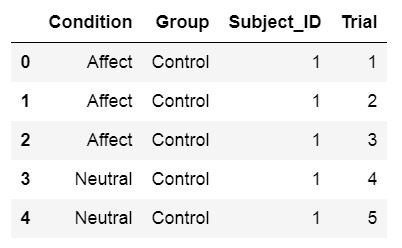
If the dataset is quite small it is possible to create a dataframe directly using Python and Pandas:
import pandas as pd
# Create some variables
trials = [1, 2, 3, 4, 5, 6]
subj_id = [1]*6
group = ['Control']*6
condition = ['Affect']*3 + ['Neutral']*3
# Create a dictionairy
data = {'Condition':condition, 'Subject_ID':subj_id,
'Trial':trials, 'Group':group}
# Create the dataframe
df = pd.DataFrame(data)
df.head()
Crunching in data by hand when the datasets are large is, however, very time-consuming and nothing to recommend. Below you will learn how to read Excel Spreadsheets and CSV files in Python and Pandas.
Loading Data Using Pandas
As mentioned above, large dataframes are usually read into a dataframe from a file. Here we will learn how to u se Pandas read_excel and read_csv methods to load data into a dataframe. There are a lot of datasets available to practice working with Pandas dataframe. In the examples below we will use some of the R datasets that can be found here.
Working with Excel Spreadsheets Using Pandas
Spreadsheets can quickly be loaded into a Pandas dataframe and you can, of course, also write a spreadsheet from a dataframe. This section will cover how to do this.
Reading Excel Files Using Pandas read_excel
One way to read a dataset into Python is using the method read_excel, which has many arguments.
pd.read_excel(io, sheet_name=0, header=0)
io is the Excel file containing the data. It should be type string data type and could be a locally stored file as well as a URL.
sheet_name can be a string for the specific sheet we want to load and integers for zero-indexed sheet positions. If we specify None all sheets are read into the dataframe.
header can be an integer or a list of integers. The default is 0 and the integer represent the row where the column names. Add None if you don’t have column names in your Excel file.
See the read_excel documentation if you want to learn about the other arguments.
Pandas Read Excel Example
Here’s a working example on how to use Pandas read_excel:
import pandas as pd
# Load a XLSX file from a URL
xlsx_source = 'http://ww2.amstat.org/publications'
'/jse/v20n3/delzell/conflictdata.xlsx'
# Reading the excel file to a dataframe.
# Note, there's only one sheet in the example file
df = pd.read_excel(xlsx_source, sheet_name='conflictdata')
df.head()
In the example above we are reading an Excel file (‘conflictdata.xlsx’). The dataset have only one sheet but for clarity we added the ‘conflictdata’ sheet name as an argument. That is, sheet_name was, in this case, nothing we needed to use.
The last line may be familiar to R users and is printing the first X lines of the dataframe:
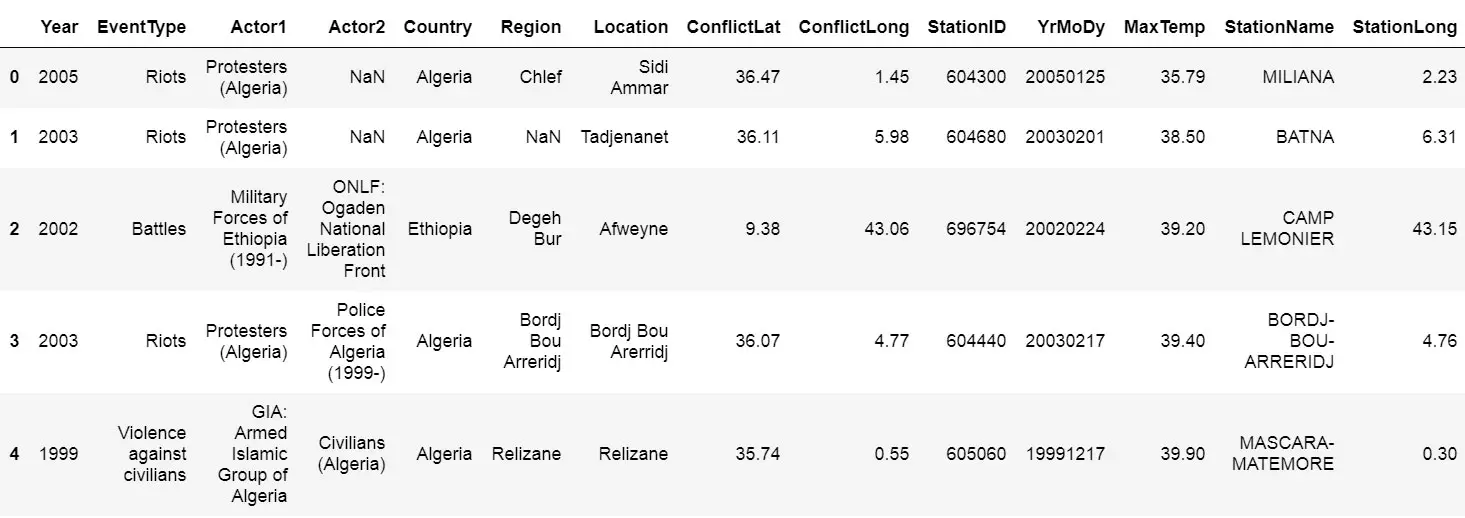
As you may have noticed we did not use the header argument when we read the Excel file above. If we set header to None we’ll get digits as column names. This, unfortunately, makes working with the Pandas dataframe a bit annoying.
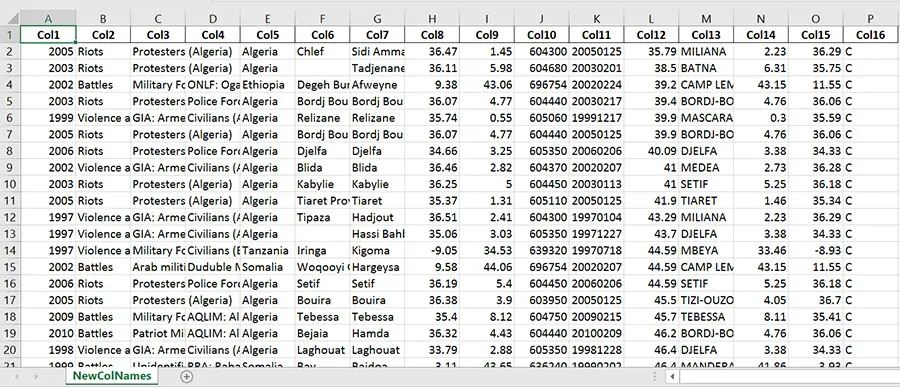
Luckily, we can pass a list of column names as an argument. Finally, as the example xlsx file contains column names we skip the first row using skiprows. Note, skiprows can be used to skip more than one row. Just add a list with the row numbers that are to be skipped.
Here’s another example how to read Excel using Python Pandas:
import pandas as pd
xlsx_source = 'http://ww2.amstat.org/publications'
'/jse/v20n3/delzell/conflictdata.xlsx'
# Creating a list of column names
col_names = ['Col' + str(i) for i in range (1, 17)]
# Reading the excel file
df = pd.read_excel(xlsx_source, sheet_name='conflictdata',
header=None, names=col_names, skiprows=[0])
df.head()
Writing Excel Files Using Pandas to_excel
We can also save a new xlsx (or overwrite the old, if we like) using Pandas to_excel method. For instance, say we made some changes to the data (e.g., aggregated data, changed the names of factors or columns) and we collaborate with other researchers. Now we don’t want to send them the old Excel file.
df.to_excel(excel_writer, sheet_name='Sheet1', index=False)
excel_writer can be a string (your file name) or an ExcelWriter object.
sheet_name should be a string with the sheet name. Default is ‘Sheet1’.
index should be a boolean (i.e., True or False). Typically, we don’t want to write a new column with numbers. Default is True.
Pandas dataframe to Excel example:
df.to_excel('newfilename.xlsx', sheet_name='NewColNames', index=False)
It was pretty simple now have written a new Excel file (xlsx) to the same directory as your Python script.
Working with CSV Files Using Pandas
Now we continue to a more common way to store data, at least in Psychology research; CSV files. We will learn how to use Python Pandas to load CSV files into dataframes.
pd.read_csv(filepath_or_buffer, sep=',')
file_path_buffer is the name of the file to be read from. The file_path_buffer can be relative to the directory that your Python script is in or absolute. It can also be a URL. What is important here that what we type in first is a string. Don’t worry we will go through this later with an example.
sep is the delimiter to use. The most common delimiter of a CSV file is comma (“,”) and it’s what delimits the columns in the CSV file. If you don’t know you may try to set it to None as the Python parsing engine will detect the delimiter.
Have a look at the if you want to learn about the other arguments.
It’s easy to read a csv file in Python Pandas. Here’s a working example on how to use Pandas read_csv:
import pandas as pd
df = pd.read_csv('https://vincentarelbundock.github.io/'
'Rdatasets/csv/psych/Tucker.csv', sep=',')
df.head()
Writing CSV Files Using Pandas to_csv
There are of course occasions when you may want to save your dataframe to csv. This is, of course, also possible with Pandas. We just use the Pandas dataframe to_csv method:
df.to_csv(path_or_buf, sep=',', index=False)
Pandas Dataframe to CSV Example:
df.to_csv('newfilename.csv', sep=';', index=False)
It was simple to export Pandas dataframe to a CSV file, right? Note, we used semicolon as separator. In some countries (e.g., Sweden) comma is used as decimal separator. Thus, this file can now be opened using Excel if we ever want to do that.
Here’s a video tutorial for reading and writing csv files using Pandas:
Now we have learned how to read and write Excel and CSV files using Pandas read_excel, to_excel, and read_csv, to_csv methods. The next section of this Pandas tutorial will continue with how to work with Pandas dataframe.
Working with Pandas Dataframe
Now that we know how to read and write Excel and CSV files using Python and Pandas we continue with working with Pandas Dataframes. We start off with basics: head and tail.
head enables us to print the first x rows. As earlier explained, by default we see the first 5 rows but. We can, of course, have a look more or less rows:
import pandas as pd
df = pd.read_csv('https://vincentarelbundock.github.io/'
'Rdatasets/csv/carData/Wong.csv', sep=',')
df.head(4)
Using tail, on the other hand, will print the x last rows of the dataframe:
df.tail(4)
Each column or variable, in a Pandas dataframe has a unique name. We can extract variables by means of the dataframe name, and the column name. This can be done using the dot sign:
piq = df.piq piq[0:4]
We can also use the [ ] notation to extract columns. For example, df.piq and df[‘piq’] is equal:

Furthermore, if we pass a list we can select more than one of the variables in a dataframe. For example, we get the two columns “piq” and “viq” ([‘piq’, ‘viq’] ) as a dataframe like this:
pviq = df[['piq', 'viq']]
How to Add a Column to Pandas Dataframe
We can also create a new variable within a Pandas dataframe, by naming it and assigning it a value. For instance, in the dataset we working here we have two variables “piq” (imathematical IQ) and “viq” (verbal IQ). We may want to calculate a mean IQ score by adding “piq” and “viq” together and then divide it by 2.
We can calculate this and add it to the df dataframe quite easy:
df['iq'] = (df['piq'] + df['viq'])/2
Alternatevily, we can calculate this using the method mean(). Here we use the argument axis = 1 so that we get the row means:
df['iq'] = df[['piq', 'viq']].mean(axis=1)
Sometimes we may want to just add a column to a dataframe without doing any calculation. It’s done in a similar way:
df['NewCol'] = ''
Remove Columns From a Dataframe
Other times we may also want to drop columns from a Pandas dataframe. For instance, the column in df that is named ‘Unnamed: 0’ is quite unnecessary to keep.
Removing columns can be done using drop. In this example we are going to add a list to drop the ‘NewCol’ and the ‘Unnamed: 0’ columns. If we only want to remove one column from the Pandas dataframe we’d input a string (e.g., ‘NewCol’).
df.drop(['NewCol', 'Unnamed: 0'], axis=1, inplace=True)
Note to drop columns, and not rows, the axis argument is set to 1 and to make the changes to the dataframe we set inplace to True.
The above calculations are great examples for when you may want to save your dataframe as a CSV file.
- If you need to reverse the order of your dataframe check my post Six Ways to Reverse Pandas Dataframe
How to Subset Pandas Dataframe
There are many methods for selecting rows of a dataframe. One simple method is by using query. This method is similar to the function subset in R.
Here’s an exemple in which we subset the dataframe where “piq” is greater than 80:
df_piq = df.query('piq > 80')
df_piq.head(4)

df_males = df[df['sex'] == 'Male']
The next subsetting example shows how to filter the dataframe with multiple criteria. In this case, we sellect observations from df where sex is male and iq is greater than 80. Note that the ampersand “&“in Pandas is the preferred AND operator.
df_male80 = df.query('iq > 80 & sex == "Male"')
It’s also possible to use the OR operator. In the following example, we filter Pandas dataframe based on rows that have a value of age greater than or equal to 40 or age less then 14. Furthermore, we we filter the dataframe by the columns ‘piq’ and ‘viq’.
df.query('age >= 40 | age < 14')[['piq', 'viq']].head()

Random Sampling Rows From a Dataframe
Using the sample method it’s also possible to draw random samples of size n from the. In the example below we draw 25random samples (n=25) and get at subset of ten obsevations from the Pandas dataframe.
df_random = df.sample(n=25)
How to Group Data using Pandas Dataframe
Now we have learned how to read Excel and CSV files to a Panda dataframe, how to add and remove columns, and subset the created dataframe.
Although subsets may come in handy there are no need for doing this when you want to look at specific groups in the data.
Pandas have a method for grouping the data which can come in handy; groupby. Especially, if you want to summarize your data using Pandas.
As an example, we can based on theory have a hypothesis that there’s a difference between men and women. Thus, in the first example we are going to group the data by sex and get the mean age, piq, and viq.
df_sex = df.groupby('sex')
df_sex[['age', 'piq', 'viq']].mean()

If we were to fully test our hypothesis we would nened to apply hypothesisis testing. Here are two posts about carrying out between-subject analysis of variance using Python:
In the next example we are going to use Pandas describe on our grouped dataframe. Using describe we will get a table with descriptive statistics (e.g., count, mean, standard deviation) of the added column ‘iq’.
df_sex[['iq']].describe()
More about summary statistics using Python and Pandas can be read in the post Descriptive Statistics using Python.
Summary of What We’ve Learned
- Working with CSV and Excel files using Pandas
- Pandas read_excel & to_excel
- Pandas read_csv & to_csv
- Working with Pandas Dataframe
- Add a column to a dataframe
- Remove a column from a dataframe
- Subsetting a dataframe
- Grouping a dataframe
There are, of course, may more things that we can do with Pandas dataframes. We usually want to explore our data with more descriptive statistics and visualizations. Make sure to check back here for more both more basic guides and in-depth guides on working with Pandas dataframe. These guides will include how to visualize data and how to carry out parametric statistics.
Leave a comment below if you have any requests or suggestions on what should be covered next!
The post A Basic Pandas Dataframe Tutorial for Beginners appeared first on Erik Marsja.