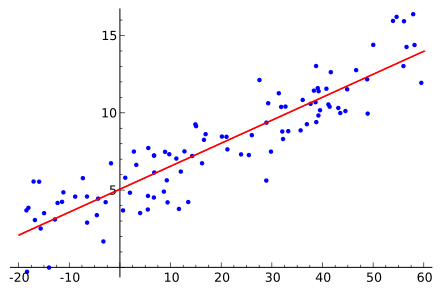
This post was originally published here In this post, we’ll walk through building linear regression models to predict housing prices resulting from economic activity. Topics covered will include: What is Regression Variable Selection Reading in the Data with pandas Ordinary Least Squares (OLS) Assumptions Simple Linear Regression Regression Plots Multiple Linear Regression Another Look at […]
Category: Data Science
K-Means & Other Clustering Algorithms: A Quick Intro with Python
This post was originally published here Clustering is the grouping of objects together so that objects belonging in the same group (cluster) are more similar to each other than those in other groups (clusters). In this intro cluster analysis tutorial, we’ll check out a few algorithms in Python so you can get a basic understanding of […]
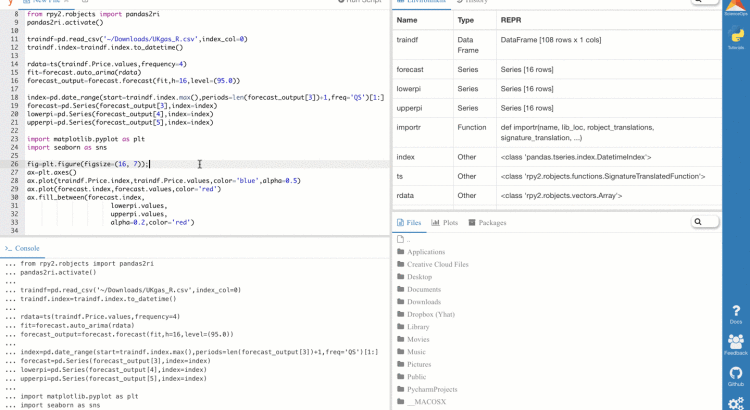
RPy2: Combining the Power of R + Python for Data Science
About Matthew: Matthew is a Data Scientist at C2FO in Kansas City. He previously studied Physics for his BS at the University of Notre Dame followed by the University of Kansas for his MS. When he is not programming, Matthew enjoys playing board games, especially Race for the Galaxy. Intro During my time as a […]
Data Science Things Roundup #7
This weeks edition of the Data Science Things Roundup is pretty python-heavy, as opposed to previous editions that were a bit more machine learning and dataviz heavy. At the end of the day, some kind of software is backing most of data science, so getting a bit lower level can be useful sometimes. This week […]
Data Science Things Roundup #6
Time again for the weekly data science things roundup. If you haven’t seen this before, check out some of the previous ones to get a feel for it. Each Tuesday I run through 3 things I’ve found interesting and bookmarked recently, generally related to python and data science (with some admitted diversions). This week is […]
Data Science Things Roundup #5
Time again for the 5th edition of the data science things roundup, named suspiciously similarly to the much more established Data Science Roundup by RJ Metrics (but we won’t worry about that this week). In previous weeks we’ve seen some pretty cool ML and Data Science libraries, mostly in python, this week we branch out […]
Which tool to learn for a better data science career
Some questions I get from new data scientists I like R a lot, so should I work towards being better at just that or should I learn excel and python and sas as well (Like a jack of all master of none)? I like R so much I wrote two books on it. Then I…
Data Science Things Roundup #4
Time for another edition of the data science things roundup, where I round up some data science things for ya’ll. Todays collections are uncharacteristically R heavy. It’s usually pretty python and machine learning heavy, so if you find something you like here, be sure to check out previous editions as well. Without further adieu: Scikit-Learn […]
Data Science Things Roundup #3
Time again for the 3rd edition of the data science things roundup, where I share a few data science things I’ve come across recently. Check out previous editions here and here. Self Organizing Maps with TensorFlow Google’s open sourcing of TensorFlow late last year caused a pretty big splash in the machine learning and data […]
Data Science Things Roundup #2
This is the second edition of the now-regular series of posts: Data Science Things Roundup, where I round up data science things (as you’d probably guessed). Last week we had a scikit-learn extension, a GUI framework for python CLIs and some writing about how kaggle winners won their competitions. This week is a bit more […]
Data Science Things Roundup #1
This is the first in a new series of posts, tailored more towards the newsletter subscribers (join it here). There are a few of these around the internet that I like, notably: ds_ldn’s Data Machina RJMetrics’ Data Science Roundup Jeremy Singer-Vine’s Data is Plural Mine will probably be way less consistent, so if you like […]
Interview with a Data Scientist Tool Developer
About Peadar: Peadar Coyle is a data scientist, author and math geek who specializes in applying robust statistical or machine learning models to data to extract business value. His academic interests range from quantum computing to time series forecasting. Peadar has worked or consulted for Amazon, Vodafone, Import.io and JobTODAY, to name a few. He […]
Over-optimizing: a story about Kaggle.
I recently took a stab at a Kaggle competition. The premise was simple, given some information about insurance quotes, predict whether or not the customer who requested the quote will follow through and buy the insurance. Straight forward classification problem, data already clean and in one place, clear scoring metric (Area under the ROC curve). […]
Weighing options with python and petersburg
In the past few weeks I’ve posted a number of examples of applications for petersburg. You can check them out here, here and here. It is, in short, an extension of probabilistic decision graphs and Bayesian networks that allows for some interesting analysis on decision theoretic problems. The interesting thing that arises out of this […]
Github.com cumulative blame in 5 lines of python
Git-pandas has gotten to be pretty capable. Currently in the master branch and soon to be in the v1.0.0 release, we’ve included a github.com interface to git-pandas via the GitHubProfile class. With this, in just a few lines of code, you can see how your profile has grown over time: from gitpandas.utilities.plotting import plot_cumulative_blame from […]