by Dan Saber | April 19, 2017 This post originally appeared on Dan Saber’s blog. We thought it was hilarious, so we asked him if we could repost it. He generously agreed! About Dan: My name is Dan Saber. I’m a UCLA math grad, and I do Data Science at Coursera. (Before that, I worked […]
Author: yhat
Data Wrangling 101: Using Python to Fetch, Manipulate & Visualize NBA Data
by Viraj Parekh | April 6, 2017 This is a basic tutorial using pandas and a few other packages to build a simple datapipe for getting NBA data. Even though this tutorial is done using NBA data, you don’t need to be an NBA fan to follow along. The same concepts and techniques can be […]
A Magical Introduction to Classification Algorithms
by Bryan Berend | March 23, 2017 About Bryan: Bryan is the Lead Data Scientist at Nielsen. Introduction When you first start learning about data science, one of the first things you learn about are classification algorithms. The concept behind these algorithms is pretty simple: take some information about a data point and place the […]
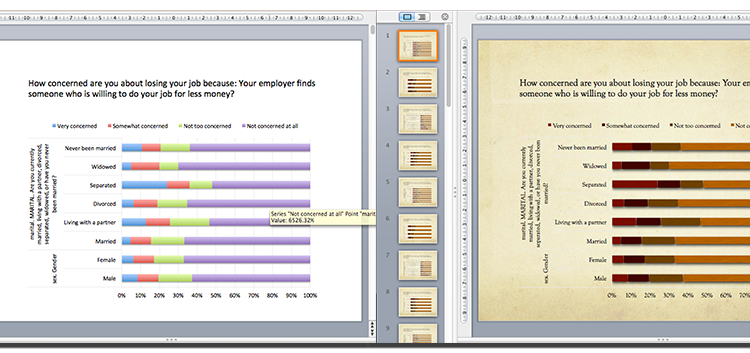
Automatic generation of large PowerPoint decks from survey data with Quantipy Python package
by Geir Freysson | March 21, 2017 About Geir: Geir is the co-founder and CEO of Datasmoothie, a tech company that brings the joy back into statistical analysis. Geir is also a caffeine enthusiast and Internet addict. Introduction How is the President doing in the latest polls? Are your employees happy? Is this medicine working? […]
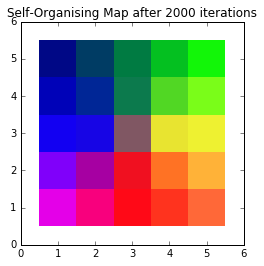
Self-Organising Maps: In Depth
About David: David Asboth is a Data Scientist with a software development background. He’s had many different job titles over the years, with a common theme: he solves human problems with computers and data. This post originally appeared on his blog, davidasboth.com Introduction In Part 1, I introduced the concept of Self-Organising Maps (SOMs). Now […]
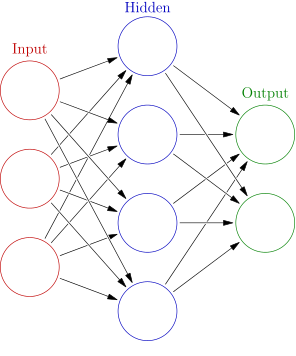
Self-Organising Maps: An Introduction
About David: David Asboth is a Data Scientist with a software development background. He’s had many different job titles over the years, with a common theme: he solves human problems with computers and data. This post originally appeared on his blog, davidasboth.com Introduction When you learn about machine learning techniques, you usually get a selection […]

Isochrones using the Google Maps Distance Matrix API
by Drew Fustin | March 9, 2017 About Drew: Drew is the Lead Data Scientist at SpotHero, an on-demand solution to help drivers find their perfect parking spot, reserved ahead of time often at rates much lower than you’d find if you just drove up to the garage. He’s also worked at Digital H2O and […]
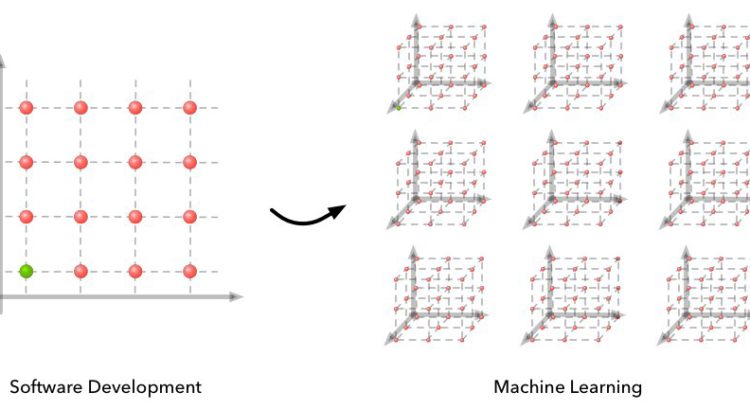
The Current State of Automated Machine Learning
About Matthew: Matthew Mayo is a Data Scientist and the Deputy Editor of KDnuggets, as well as a machine learning aficionado and an all-around data enthusiast. Matthew holds a Master’s degree in Computer Science and a graduate diploma in Data Mining. This post originally appeared on the KDNuggets blog. Background What is automated machine learning […]
A Simple Trending Products Recommendation Engine in Python
by Chris Clark | February 28, 2017 This blogpost originally appeared on Chris Clark’s blog. Chris is the cofounder of Grove Collaborative, a certified B-corp that delivers amazing, affordardable and effective natural products to your doorstep. We’re fans. Background Our product recommendations at Grove.co were boring. I knew that because our customers told us. When […]
Beginner’s Guide to Customer Segmentation
In this post I’m going to talk about something that’s relatively simple but fundamental to just about any business: Customer Segmentation. At the core of customer segmentation is being able to identify different types of customers and then figure out ways to find more of those individuals so you can… you guessed it, get more […]
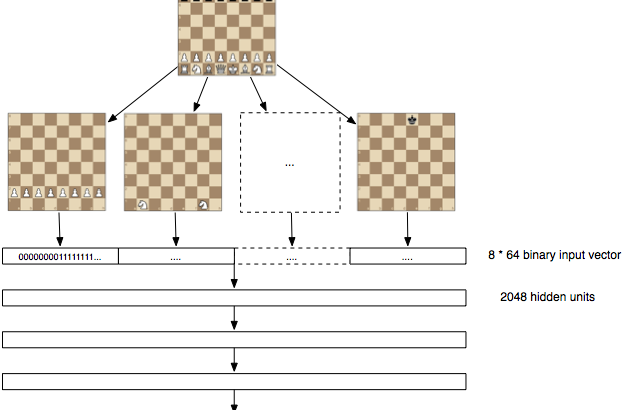
Deep Learning for … Chess
by Erik Bernhardsson | February 2, 2017 About Erik: Dad and CTO (Chief Troll Officer) at a fintech startup in NYC. Ex-Spotify, co-organizing NYC ML meetup, open source sometimes (Luigi, Annoy), blogs random stuff Deep learning for… chess I’ve been meaning to learn Theano for a while and I’ve also wanted to build a chess […]

Becoming a Data Scientist
This blogpost is an excerpt of Springboard’s free guide to data science jobs and originally appeared on the Springboard blog. Data Science Skills Most data scientists use a combination of skills every day, some of which they have taught themselves on the job or otherwise. They also come from various backgrounds. There isn’t any one […]
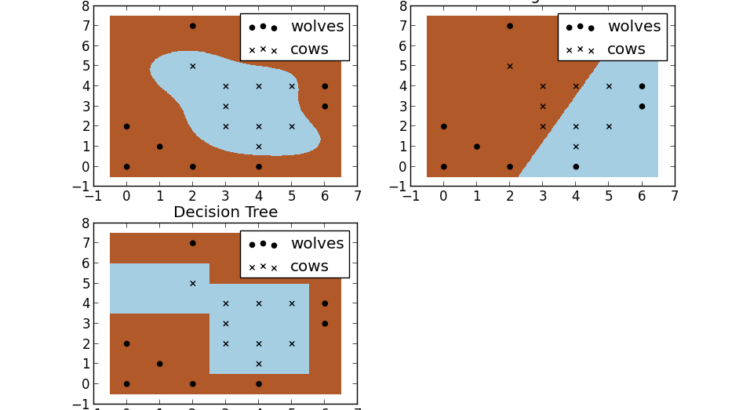
Why use SVM?
Support Vector Machine has become an extremely popular algorithm. In this post I try to give a simple explanation for how it works and give a few examples using the the Python Scikits libraries. All code is available on Github. I’ll have another post on the details of using Scikits and Sklearn. What is SVM? […]

Applied Data Science
How can data science improve products? What are predictive models? How do you go from insight to prototype to production application? This is an excerpt from “Applied Data Science,” A Yhat whitepaper about data science teams and how companies apply their insights to the real world. You’ll learn how successful data science teams are composed […]
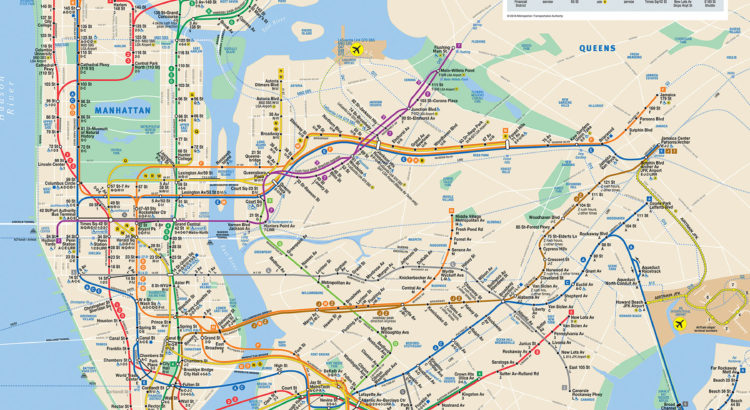
NYC Subway Math
About Erik: Dad and CTO (Chief Troll Officer) at a fintech startup in NYC. Ex-Spotify, co-organizing NYC ML meetup, open source sometimes (Luigi, Annoy), blogs random stuff NYC Subway math Apparently MTA (the company running the NYC subway) has a real-time API. My fascination for the subway takes autistic proportions and so obviously I had […]