It’s been a little while since I’ve posted anything about git-pandas, as I’ve been working on getting a sister project, twitter-pandas up and running. Work has continued though, and today I’d like to show a currently experimental feature, parallelized cumulative blame.
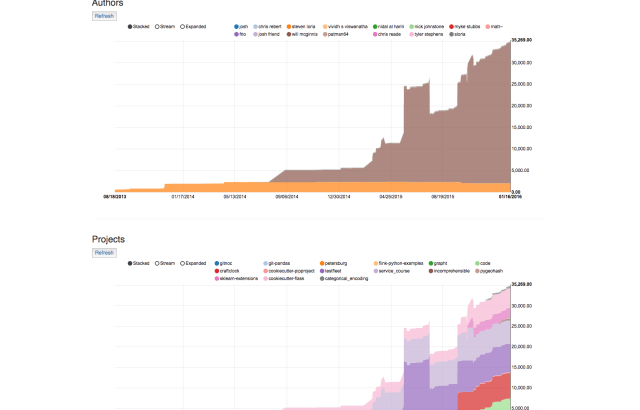
Cumulative blame is one of the more popular features used in git-pandas, as it can be used to easily create a pretty interesting plot that shows the growth of a project over time.

One downside of this particular feature though, is that it’s pretty damn slow. For every repo in the project and for every revision in each of those repos, the relatively expensive “git blame” operation has to be executed. There are ways to speed up the calculation at the cost of resolution or accuracy, but at the end of the day, it’s still pretty slow.
The operation is also, however, embarrassingly parallel. Each and every rev can be blamed completely independently of each other, and those calls are largely bound by computation outside of the python process itself (rather, it’s in git itself). Because of this, we can actually use multithreading pretty easily to have low-overhead parallelism in python despite the GIL.
An easy way to do this is with the great joblib library. Using their example:
from joblib import Parallel Parallel(n_jobs=2, backend="threading")(delayed(sqrt)(i ** 2) for i in range(10)) >>> [0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0]
Using this method (I haven’t been able to get a multiprocessing based-backend to work yet), I’ve implemented an experimental parallel_cumulative_blame() method in just the Repository object in git-pandas. You can check out the code here: https://github.com/wdm0006/git-pandas/blob/master/gitpandas/repository.py#L662. It’s not been released to PyPI quite yet, but should be in the coming days (along with a few other things).
Using a simple example script:
from gitpandas import Repository import time g = Repository(working_dir='..') st = time.time() blame = g.cumulative_blame(branch='master', extensions=['py', 'html', 'sql', 'md'], limit=None, skip=None) print(blame.head()) print(time.time() - st) st = time.time() blame = g.parallel_cumulative_blame(branch='master', extensions=['py', 'html', 'sql', 'md'], limit=None, skip=None, workers=4) print(blame.head()) print(time.time() - st)
We can see that with 4 workers, we accomplish approximately a 3x speedup in cumulative blame performance. Not too bad.
If anyone would like to help with performance optimization of some of the costlier operations in git-pandas, or with the continued development of it’s core, comment below and get involved. We have a few planned improvements underway in preparation for a v2.0.0 release in the coming months.
The post Parallelizing cumulative blame in git-pandas with joblib appeared first on Will’s Noise.