As part of your code, you may be inclined to call a command to do something. But is it always a good idea? How to do it safely? What happens behind the scenes? This article is written from a general perspective, with a Unix/C bias and a very slight Python bias. The problems mentioned apply […]
Category: Data Structures

Understanding SettingwithCopyWarning in pandas
SettingWithCopyWarning is one of the most common hurdles people run into when learning pandas. A quick web search will reveal scores of Stack Overflow questions, GitHub issues and forum posts from programmers trying to wrap their heads around what this warning means in their particular situation. It’s no surprise that many struggle with this; there […]
Building An Analytics Data Pipeline In Python
If you’ve ever wanted to work with streaming data, or data that changes quickly, you may be familiar with the concept of a data pipeline. Data pipelines allow you transform data from one representation to another through a series of steps. Data pipelines are a key part of data engineering, which we teach in our […]
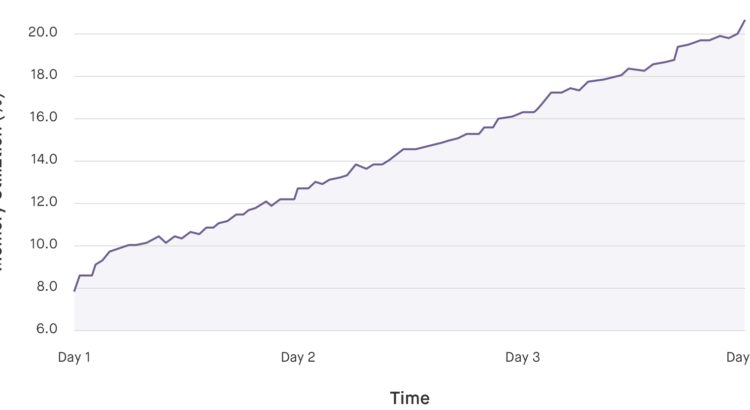
Diagnosing and Fixing Memory Leaks in Python
Fugue uses Python extensively throughout the Conductor and in our support tools, due to its ease-of-use, extensive package library, and powerful language tools. One thing we’ve learned from building complex software for the cloud is that a language is only as good as its debugging and profiling tools. Logic errors, CPU spikes, and memory leaks […]

Introduction to MongoDB and Python
Python is a powerful programming language used for many different types of applications within the development community. Many know it as a flexible language that can handle just about any task. So, what if our complex Python application needs a database that’s just as flexible as the language itself? This is where NoSQL, and specifically […]
Debugging Your Operating System: A Lesson In Memory Allocation
It began, as so many investigations do, with a bug report. The name of the bug report was simple enough: “iter_content slow with large chunk size on HTTPS connection”. This is the kind of name of a bug report that immediately fires alarm bells in my head, for two reasons. Firstly, it’s remarkably difficult to […]

Pandas Cheat Sheet for Data Science in Python
by Karlijn Willems | November 30, 2016 This post originally appeared on the DataCamp blog. Big thanks to Karlijn and all the fine folks at DataCamp for letting us share with the Yhat audience! Pandas library The Pandas library is one of the most preferred tools for data scientists to do data manipulation and analysis, […]
Flask by Example – Custom Angular Directive with D3
Welcome back. With Angular set up along with a loading spinner and our refactored Angular controller, let’s move on to the final part and create a custom Angular Directive to display a frequency distribution chart with JavaScript and the D3 library. Remember: Here’s what we’re building – A Flask app that calculates word-frequency pairs based […]

Work Smarter and Not Harder
by Brian Mitchell, Mango Solutions Here at Mango we take testing very seriously and as the automated tester in the company I take it more seriously than most. Automated testing does exactly what it says on the tin, it allows you to automate a number of test scenarios. We use specialised software to simulate mouse […]
Integrating Python and R into a Data Analysis Pipeline – Part 1
By Chris Musselle and Kate Ross-Smith For a conference in the R language, EARL London 2015 saw a surprising number of discussions about Python. I like to think that at least some of this was to do with the fact that the day before the conference, we ran a 3-hour workshop outlining various strategies […]
HTTP/2.0 For Python
The HTTPbis have spoken, HTTP/2.0 is happening. Major websites are beginning to adopt it (hello there Twitter!), and the spec is beginning to get nailed down. If you’re unfamiliar with HTTP/2.0 and all the fun things it brings you, Ilya Grigorik has been doing an excellent job evangelising for it. Take a look at this […]
Beautiful Native Libraries
I’m obsessed with nice APIs. Not just APIs however, also in making the overall experience of using a library as good as possible. For Python there are quite a few best practices around by now but it feels like there is not really a lot of information available about how to properly structure a native […]

Yup, This Blog is Now Powered by Pelican
As an open source “Plone guy”, I’m always prepared to defend and explain my choice to not use Plone for blogging. As an open source “Plone guy”, I’m always prepared to defend and explain my choice to not use Plone for blogging. A couple years ago, I started using WordPress in order to learn its […]
Dealing with the Python Import Blackbox
Turns out, this does not work reliably, in fact it will only work when packages are involved. I originally wrote the core for Flask extensions and it appeared to work, but I never verified that it works without extensions being involved. And in fact the module cleanup breaks it. Apparently Python does clean it up […]
April 1st Post Mortem
This year I decided to finally do what I planned for quite some time: an April’s fool joke. (I did contribute a bit to PEP 3117, but that does not count). This year I decided to make a little joke about Python microframeworks (micro-web-frameworks?) and wrote a little thing, and created a website and screencast […]