Hey all, I haven’t done one of these in quite a while, but thought I’d share a few more articles I’ve found interesting recently. An analysis of twitter influencers in the field of data science & big data This is a pretty in depth medium article that goes through some of the concepts in network […]
Category: Statistics

NumPy Cheat Sheet – Python for Data Science
NumPy is the library that gives Python its ability to work with data at speed. Originally, launched in 1995 as ‘Numeric,’ NumPy is the foundation on which man importany Python data science libraries are built, including Pandas, SciPy and scikit-learn. The printable version of this cheat sheet It’s common when first learning NumPy to have […]
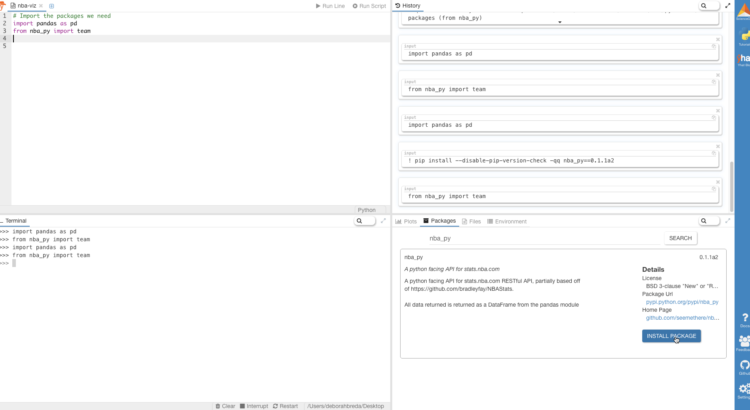
Data Wrangling 101: Using Python to Fetch, Manipulate & Visualize NBA Data
by Viraj Parekh | April 6, 2017 This is a basic tutorial using pandas and a few other packages to build a simple datapipe for getting NBA data. Even though this tutorial is done using NBA data, you don’t need to be an NBA fan to follow along. The same concepts and techniques can be […]

How to do Descriptives Statistics in Python using Numpy
In this short post we are going to revisit the topic on how to carry out summary/descriptive statistics in Python. In the previous post, I used Pandas (but also SciPy and Numpy, see Descriptive Statistics Using Python) but now we are only going to use Numpy. The descriptive statistics we are going to calculate are […]

How to do Descriptive Statistics in Python using Numpy
In this short post we are going to revisit the topic on how to carry out summary/descriptive statistics in Python. In the previous post, I used Pandas (but also SciPy and Numpy, see Descriptive Statistics Using Python) but now we are only going to use Numpy. The descriptive statistics we are going to calculate are […]
A Magical Introduction to Classification Algorithms
by Bryan Berend | March 23, 2017 About Bryan: Bryan is the Lead Data Scientist at Nielsen. Introduction When you first start learning about data science, one of the first things you learn about are classification algorithms. The concept behind these algorithms is pretty simple: take some information about a data point and place the […]
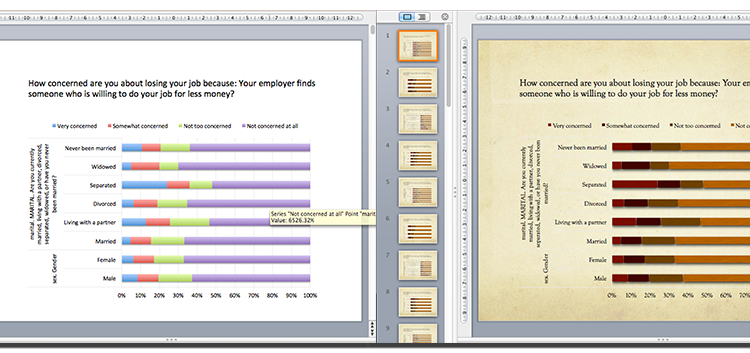
Automatic generation of large PowerPoint decks from survey data with Quantipy Python package
by Geir Freysson | March 21, 2017 About Geir: Geir is the co-founder and CEO of Datasmoothie, a tech company that brings the joy back into statistical analysis. Geir is also a caffeine enthusiast and Internet addict. Introduction How is the President doing in the latest polls? Are your employees happy? Is this medicine working? […]

How to Write a Collectd Plugin with Python
Collectd is a system statistics collection daemon. It gathers a lot of information about the system it’s running on, and passes it on to a software that can process and visualize that information, e.g. Grafana. Collectd already brings along a lot of built-in plugins to gather information about the system load, the network traffic, available […]
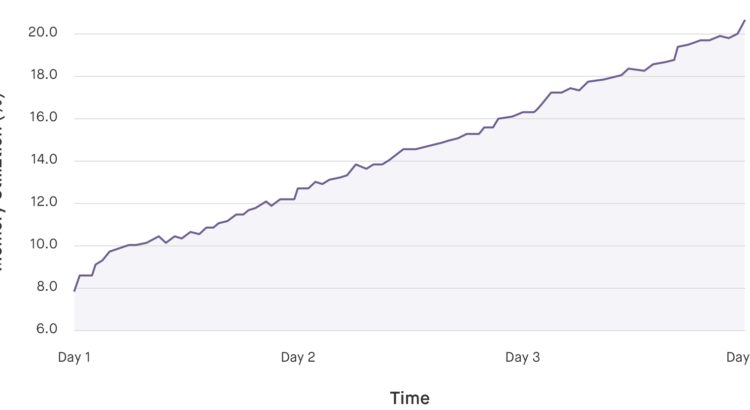
Diagnosing and Fixing Memory Leaks in Python
Fugue uses Python extensively throughout the Conductor and in our support tools, due to its ease-of-use, extensive package library, and powerful language tools. One thing we’ve learned from building complex software for the cloud is that a language is only as good as its debugging and profiling tools. Logic errors, CPU spikes, and memory leaks […]
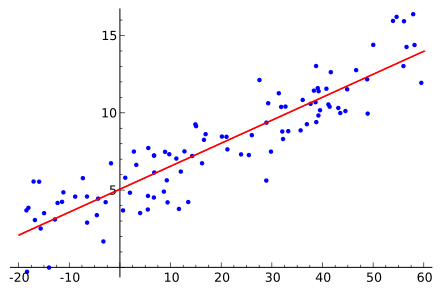
Predicting Housing Prices with Linear Regression using Python, pandas, and statsmodels
This post was originally published here In this post, we’ll walk through building linear regression models to predict housing prices resulting from economic activity. Topics covered will include: What is Regression Variable Selection Reading in the Data with pandas Ordinary Least Squares (OLS) Assumptions Simple Linear Regression Regression Plots Multiple Linear Regression Another Look at […]

Pandas Cheat Sheet – Python for Data Science
Pandas is arguably the most important Python package for data science. Not only does it give you lots of methods and functions that make working with data easier, but it has been optimized for speed which gives you a significant advantage compared with working with numeric data using Python’s built-in functions. The printable version of […]

Becoming a Data Scientist
This blogpost is an excerpt of Springboard’s free guide to data science jobs and originally appeared on the Springboard blog. Data Science Skills Most data scientists use a combination of skills every day, some of which they have taught themselves on the job or otherwise. They also come from various backgrounds. There isn’t any one […]

What is Data Engineering?
This is the first in a series of posts on Data Engineering. If you like this and want to know when the next post in the series is released, you can subscribe at the bottom of the page. From helping cars drive themselves to helping Facebook tag you in photos, data science has attracted a […]

Applied Data Science
How can data science improve products? What are predictive models? How do you go from insight to prototype to production application? This is an excerpt from “Applied Data Science,” A Yhat whitepaper about data science teams and how companies apply their insights to the real world. You’ll learn how successful data science teams are composed […]
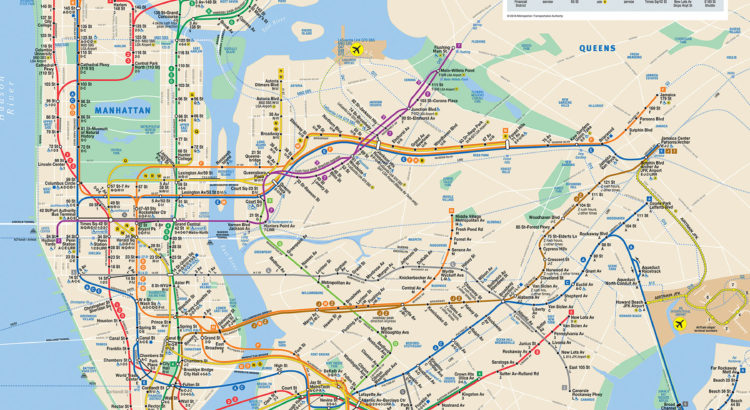
NYC Subway Math
About Erik: Dad and CTO (Chief Troll Officer) at a fintech startup in NYC. Ex-Spotify, co-organizing NYC ML meetup, open source sometimes (Luigi, Annoy), blogs random stuff NYC Subway math Apparently MTA (the company running the NYC subway) has a real-time API. My fascination for the subway takes autistic proportions and so obviously I had […]