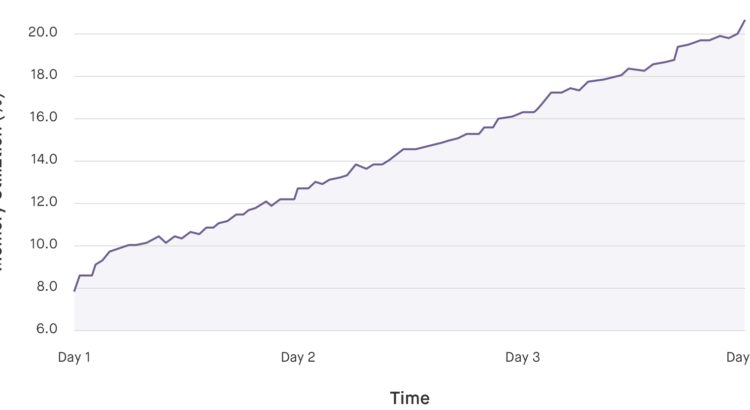
Fugue uses Python extensively throughout the Conductor and in our support tools, due to its ease-of-use, extensive package library, and powerful language tools. One thing we’ve learned from building complex software for the cloud is that a language is only as good as its debugging and profiling tools. Logic errors, CPU spikes, and memory leaks […]
Category: NumPy
A Simple Trending Products Recommendation Engine in Python
by Chris Clark | February 28, 2017 This blogpost originally appeared on Chris Clark’s blog. Chris is the cofounder of Grove Collaborative, a certified B-corp that delivers amazing, affordardable and effective natural products to your doorstep. We’re fans. Background Our product recommendations at Grove.co were boring. I knew that because our customers told us. When […]

Pandas Cheat Sheet – Python for Data Science
Pandas is arguably the most important Python package for data science. Not only does it give you lots of methods and functions that make working with data easier, but it has been optimized for speed which gives you a significant advantage compared with working with numeric data using Python’s built-in functions. The printable version of […]
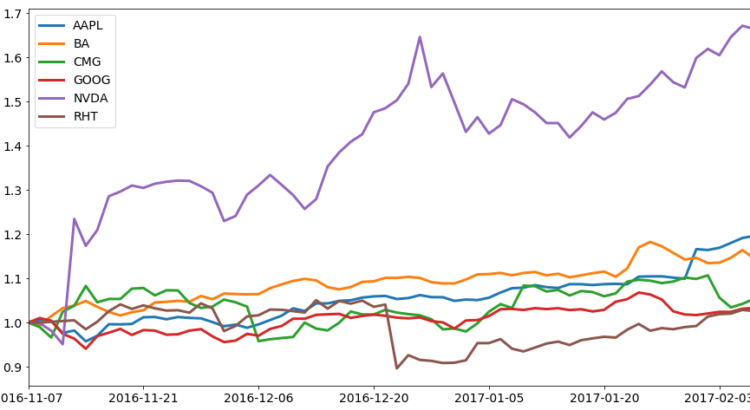
1 tip for effective data visualization in Python
Yes, you read correctly – this post will only give you 1 tip. I know most posts like this have 5 or more tips. I once saw a post with 15 tips, but I may have been daydreaming at the time. You’re probably wondering what makes this 1 tip so special. “Vik”, you may ask, […]

Becoming a Data Scientist
This blogpost is an excerpt of Springboard’s free guide to data science jobs and originally appeared on the Springboard blog. Data Science Skills Most data scientists use a combination of skills every day, some of which they have taught themselves on the job or otherwise. They also come from various backgrounds. There isn’t any one […]
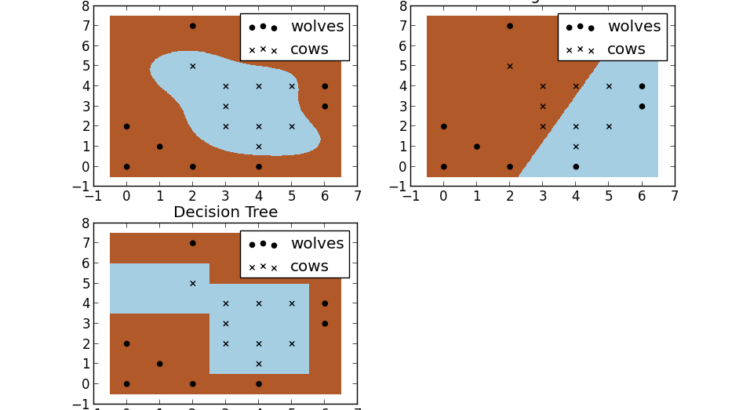
Why use SVM?
Support Vector Machine has become an extremely popular algorithm. In this post I try to give a simple explanation for how it works and give a few examples using the the Python Scikits libraries. All code is available on Github. I’ll have another post on the details of using Scikits and Sklearn. What is SVM? […]
How to present your data science portfolio on Github
This is the fifth and final post in a series of posts on how to build a Data Science Portfolio. In the previous posts in our portfolio series, we talked about how to build a storytelling project, how to create a data science blog, how to create a machine learning project, and how to construct […]
Machine Learning Walkthrough Part One: Preparing the Data
Cleaning and preparing data is a critical first step in any machine learning project. In this blog post, Dataquest student Daniel Osei’s takes us through examining a dataset, selecting columns for features, exploring the data visually and then encoding the features for machine learning. This post is based on a Dataquest ‘Monthly Challenge’, where our […]
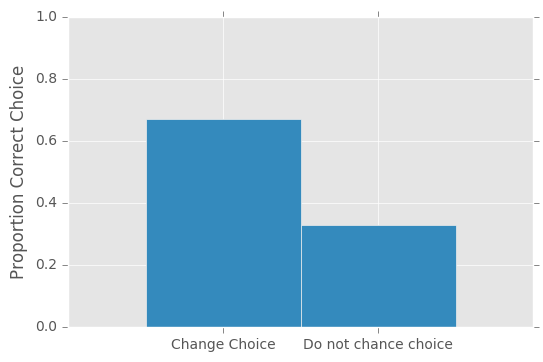
Simulating the Monty Hall Problem
I’ve been hearing about the Monty Hall problem for years and its never quite made sense to me, so I decided to program up a quick simulation. In the Monty Hall problem, there is a car behind one of three doors. There are goats behind the other two doors. The contestant picks one of the […]
Top 10 Python libraries of 2016
Last year, we did a recap with what we thought were the best Python libraries of 2015, which was widely shared within the Python community (see post in r/Python). A year has gone by, and again it is time to give due credit for the awesome work that has been done by the open source […]
BaseN Encoding and Grid Search in category_encoders
In the past I’ve posted about the various categorical encoding methods one can use for machine learning tasks, like one-hot encoding, ordinal or binary. In my OSS package, category_encodings, I’ve added a single scikit-learn compatible encoder called BaseNEncoder, which allows the user to pick a base (2 for binary, N for ordinal, 1 for one-hot, […]

Pandas Cheat Sheet for Data Science in Python
by Karlijn Willems | November 30, 2016 This post originally appeared on the DataCamp blog. Big thanks to Karlijn and all the fine folks at DataCamp for letting us share with the Yhat audience! Pandas library The Pandas library is one of the most preferred tools for data scientists to do data manipulation and analysis, […]
Selenium + PhantomJS Tutorial
This post borrows from the previous selenium-based post here. If you have heard of PhantomJS, would like to try it out, and are curious to see how it performs against other browsers such as Chrome, this post will help. However, in my experience, using the PhantomJS browser for webscraping doesn’t really have many benefits compared […]
Scraping Financial Data with Selenium
Note: The following post is a significant step up in difficulty from the previous selenium-based post, Automate Your Browser: A Guided Selenium Adventure. Please see the start of that post for links on getting selenium set up if this is your first time using it. If you really do need financial data, there are likely […]
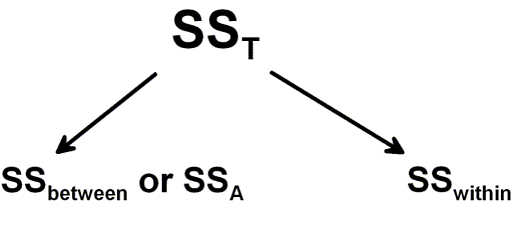
Four ways to conduct one-way ANOVA with Python
The current post will focus on how to carry out between-subjects ANOVA using Python. As mentioned in an earlier post (Repeated measures ANOVA with Python) ANOVAs are commonly used in Psychology. We start with some brief introduction on theory of ANOVA. If you are more interested in the four methods to carry out one-way […]